



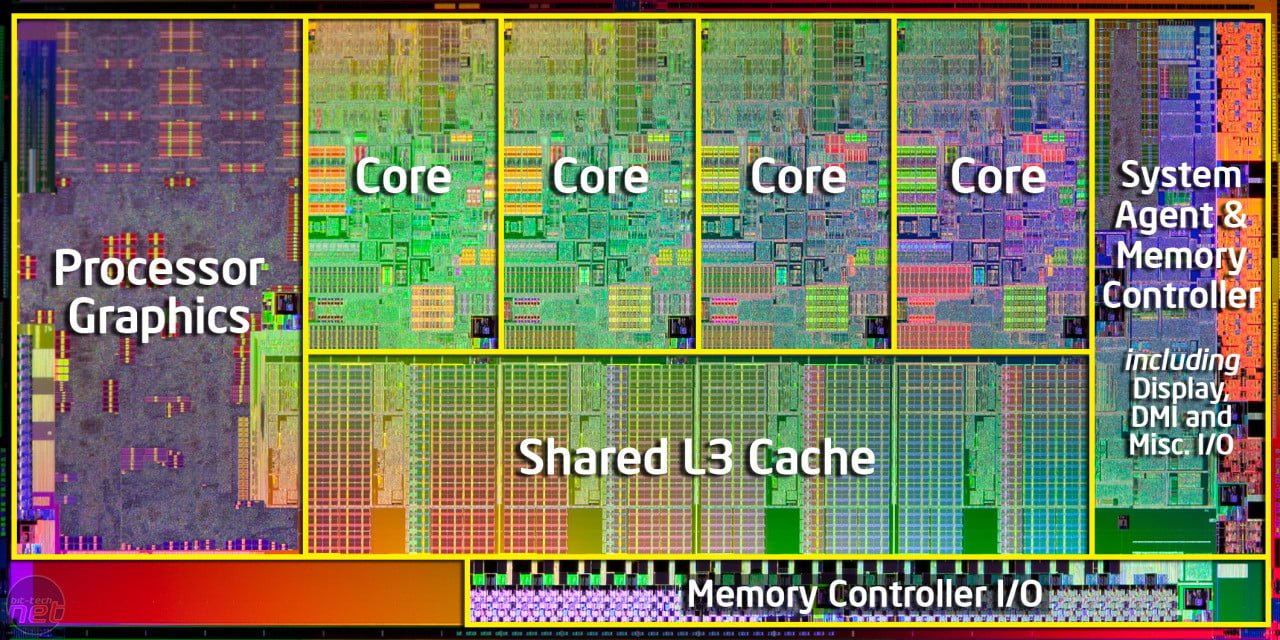
یکی از مهمترین موارد زیر پوستی در دنیای کامپیوترها، عدم تعامل کافی بین سخت افزار و نرم افزار است؛ به طوری که در حال حاضر به دلایل بسیار نرم افزارها توانایی لازم جهت استفاده از حداکثر توان و پرفورمنس سخت افزار ها را دارا نیستند. به عنوان مثال می توان به کتابخانه های سطح پایین (API) اشاره کرد؛ آخرین و معتبر ترین API های موجود مانند Vulkan و DX12 به همین منظور تولید شده اند. کاهش سربارهای پردازشی، کنترل سرریز ها و استفاده بهینه از قابلیت هایی همچون Hyper threading مهمترین تمرکز این API ها را در بهبود ویرایشی تشکیل می دهند. از آن بدتر، مدیریت سیستم عامل ها (OS) است. بسیاری از اطلاعات موجود در زمینه مدیریت پردازنده (CPU) و حافظه های رم (RAM) توسط سیستم عامل ها در هاله ای از ابهام قرار دارد و بسیاری از مطالب موجود در این زمینه، تنها احتمالات و حدس و گمان است. یکی از مهمترین بخش های این نظریه به مدیریت هسته های پردازنده (CPU Core) می پردازد. این مقوله از آنجایی مهم می گردد که سیستم عامل و نرم افزار وظیفه مدیریت هسته های پردازنده در لودهای سنگین را بر عهده دارند و هر هسته به طور مجزا توسط یک اکوسیستم نرم افزاری متشکل از سیستم عامل و نرم افزاری خاص کنترل می گردد. به عنوان مثال پردازنده هایی همچون Haswell-EX Xeon E7 V3 از 18 هسته برخوردار هستند و قیمت نهایی آنها نسبتا بالا است. شکست محدودیت های پردازنده های چند هسته ای (Breaking the Multicore Bottleneck) به تازگی بسیار مورد توجه جوامع آکادمیک از جمله دانشگاه “ایالتی کارولینای شمالی” قرار گرفته است.
محققان این دانشگاه معتقدند که این مشکل حتی در پردازنده و پلتفرم های مدرن امروزی نیز دیده می شود؛ راه حل آنها در این زمینه شامل مجموعه ای اختصاصی از “مدارهای منطقی” و Queue Management Device است. آزمون های این محققان حاکی از آن است که می توان به روش هایی متشکل از QMD و “کنترل صفوف نرم افزاری” ارتباط بین هسته های پردازنده را تقویت نموده و حتی سرعت پردازش های میان هسته ای را تا 2 برابر افزایش داد. در دهه گذشته هر پردازنده شامل چندین ریز پردازنده در یک قالب است؛ این مهم است که بدون افزایش تعداد هسته ها در قالب های (Bloc) بتوان ضمن کاهش توان حرارتی (TDP)، عملکرد پردازشی و بالانس هسته ها را به وسیله نرم افزار کنترل نمود. اما این راه حل نیز مشکلات خود را به همراه دارد؛ به عنوان مثال برنامه های نرم افزاری موجود هستند که نویسندگان آنها کار را بر روی هسته های مختلف تقسیم کرده اند. در نتیجه یک یا چند هسته در یک پریود زمانی هر چند کوتاه، در انتظار دستوری خاص Park می شود. در این حالت نمی توان تقصیر را بر گردن طراحی انداخت. در شیوه ای دیگر، حرکت از هسته ای به هسته دیگر است که عمدتا در بین برنامه نویسان رواج ندارد. بدین ترتیب که بخش از پردازش بر عهده هسته اول و بخشی دیگر را هسته ای دیگر بر عهده می گیرد.
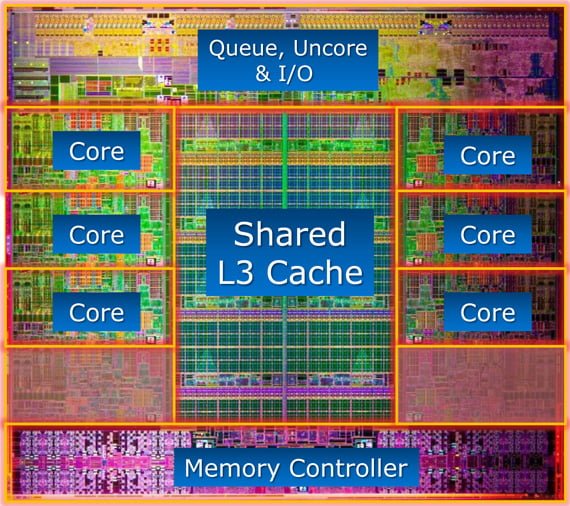
به منظور جلوگیری از بیکار ماندن هسته ها و ارتکاب خطاهای معمول، پردازنده ها از یک فناوری تحت عنوان Lock-protected Software Queues بهره می برند. این “ساختمان داده” است که با توجه به قوانین نرم افزار، هماهنگی و دسترسی به اطلاعات را معین می کند. اما زمانی که یک نرم افزار با سربار پردازشی قابل توجه اجرا می گردد، ارتباط بین هسته با تنگنا مواجه می شود. اینتل (Intel) به کمک چند دانشگاه آمریکایی و فعال در زمینه های دانشکده برق، الکترونیک، نرم افزار و سخت افزار، چند پروژه تحقیقاتی را رقم زده است. این پروژه ها در همین راستا استارت خورده و هدف آنها هماهنگ سازی صف هسته در پردازش های سنگین است. آرایش QMD دارای تعریف بسیار ساده ای است اما پیاده سازی آن به طور کلی در تمامی نرم افزارها به همین سادگی نخواهد بود!
افزودن داده ها به صف و انتقال به Core
فراخوانی داده توسط Core و نشست اولیه حافظه های کش (Cache)
جایگزین کردن نزدیک ترین داده ها به جای داده قبلی و ارسال سریع آن به هسته
نزدیک ترین الگوریتمی که به ذهن شما رسیده است چیست؟ بله، درست است پردازش “گره” یا Node در بسته های شبکه که عمدتا دارای ظاهر یکسان هستند. جالب است بدانید که پس از پیاده سازی مناسب QMD در یک پردازنده 16 هسته ای اینتل، سرعت پردازش بسته های شبکه 20 بار در زمان بیشتر شده بود. گوگل (Google) یک پروژه مشابه را ایجاد کرده است که ظاهرا در سرورهای خود مورد استفاده قرار می دهد. در این روش خبری از QMD نبوده و برای هر هسته یک کار خاص در نظر گرفته شده است. توزیع کار با یک الویت بندی جالب توجه به هسته هایی می رسد که پیشگام از نظر پردازش هستند. نرم افزار هسته هایی را انتخاب می کند که کارهای در دست اجرا را تمام کرده و در مدت زمان بسیار کوتاه نزدیک ترین پردازش که از پیش مشخص و علامت گذاری شده است، به سوی هسته هدایت می شود. با وجود آنکه محققانی از دانشگاه های MIT مانند Srini Devadas که متخصص در زمینه حافظه نهان (Cache) است با فناوری QMD مخالف است، اما اینتل برای پیاده سازی آن شک ندارد. این منتقدان خواهان بازنویسی قوانین حافظه کش هستند. اما محققان امیدوار هستند که فناوری QMD بتواند مفهوم ارتباط بین هسته و CPU input/output system را ساده تر نماید. در عین حال ابداع “شتاب دهنده های سخت افزاری” با بهبود عملکرد بهره وری انرژی، حرکت نرم افزارها به سمت کنترل صحیح هسته های پردازنده و Job ها، توزیع مناسب اطلاعات در بین هسته ها، الویت بندی داده های نزدیک به هسته و مورادی از این دست می تواند عملکرد یک پردازنده را به سادگی و به طور قابل توجهی افزایش دهد. این مهم بدون همکاری توسعه دهندگان سیستم عامل و نرم افزارها امکان پذیر نخواهد بود.


















جالب بود :-bd
پس کو رامین رستمی؟!!!!
جای خالی Masoud.R بشدت حس میشه دوستان.فکر کنین این دو نفر بخوان در برابر هم کنفرانس بدن.:D
روی خود پردازنده اعمال میشه دیگه:l
حالا این قراره داخل سیستم عاملها اعمال بشه یا روش برنامه نویسی عوض بشه؟؟ من درست نفهمیدم!!
زیاد مهم نیست مطمئنن اونقدری برات کار میکنه که یه سیستم دیگه بگیری تا وقتی که بخاد نابود شه …..حتی سیستم های سرورم همینجوریش بعد یه مدت عوض میشن که بروز باشن
درسته که با اجرا شدن این طرح مخصوصا ران تایم بالا میره ولی چون از حداکثر قدرت و مصرف پردازنده بیشتر استفاده میشه و نوسان فعالیت پردازنده ، باید فکری هم به حال استقامت و عمر پردازنده بکنن