



Jules Urbach مدیر عامل OTOY (کمپانی متخصص در زمینه رندر هولوگرافیک در فضای ابری) اولین بنچمارک Nvidia A100 Ampere را به اشتراک گذاشته. این گرافیک اولین و در حال حاضر تنها کارت گرافیک بر پایه Ampere میباشد (یا به شکل دقیقتر یک شتاب دهنده محاسباتی). اگر چه انویدیا اعلام کرده بود که ما به سرعت شاهد حضور سیستمهای DGX100 خواهیم بود اما تا به حال هیچ بنچمارک خاصی از A100 منتشر نشده بود.
A100 از اولین پردازنده گرافیکی 7 نانومتری تیم سبز بهره میبرد، یعنی GA100. این گرافیک از 6912 هسته CUDA و 40 گیگابایت حافظه HBM2 بهره مند است. همچنین اولین کارتی میباشد که رابط PCIe 4.0 یا SXM4 بسته به مدل را در اختیار خریداران خواهد گذاشت.
اولین بنچمارک Nvidia A100 Ampere
بنچمارک OctaneBench طراحی شده تا عملکرد OctaneRender را آزمایش کند. این رندر به شکل انحصاری برای کارت گرافیکهای انویدیا طراحی شده زیرا تنها به تکنولوژی CUDA متکی است بنابراین شاهد هیچ مقایسهای با AMD Big Navi یا کارت گرافیکهای بر پایه Arcturus نخواهیم بود. Jules Urbach اعلام کرده که A100 تا 43 درصد سریعتر از Turing است.
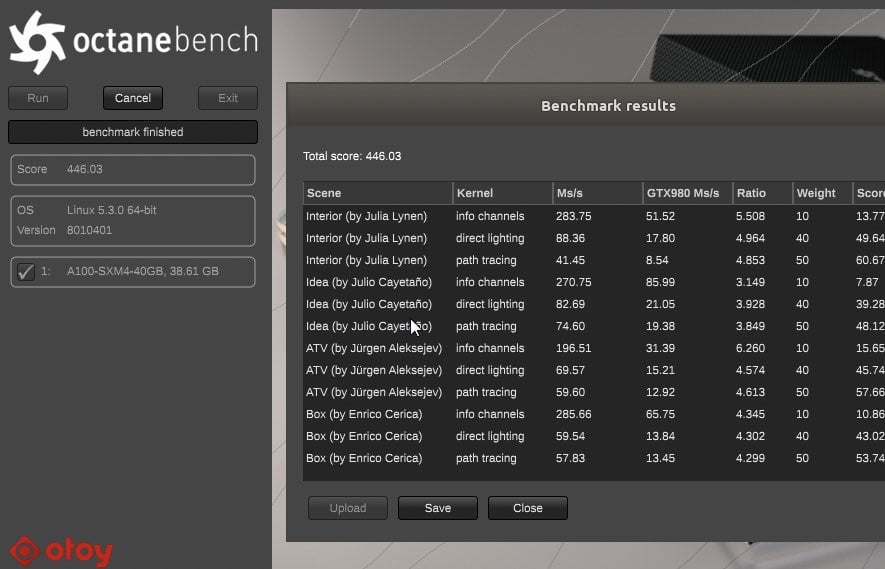
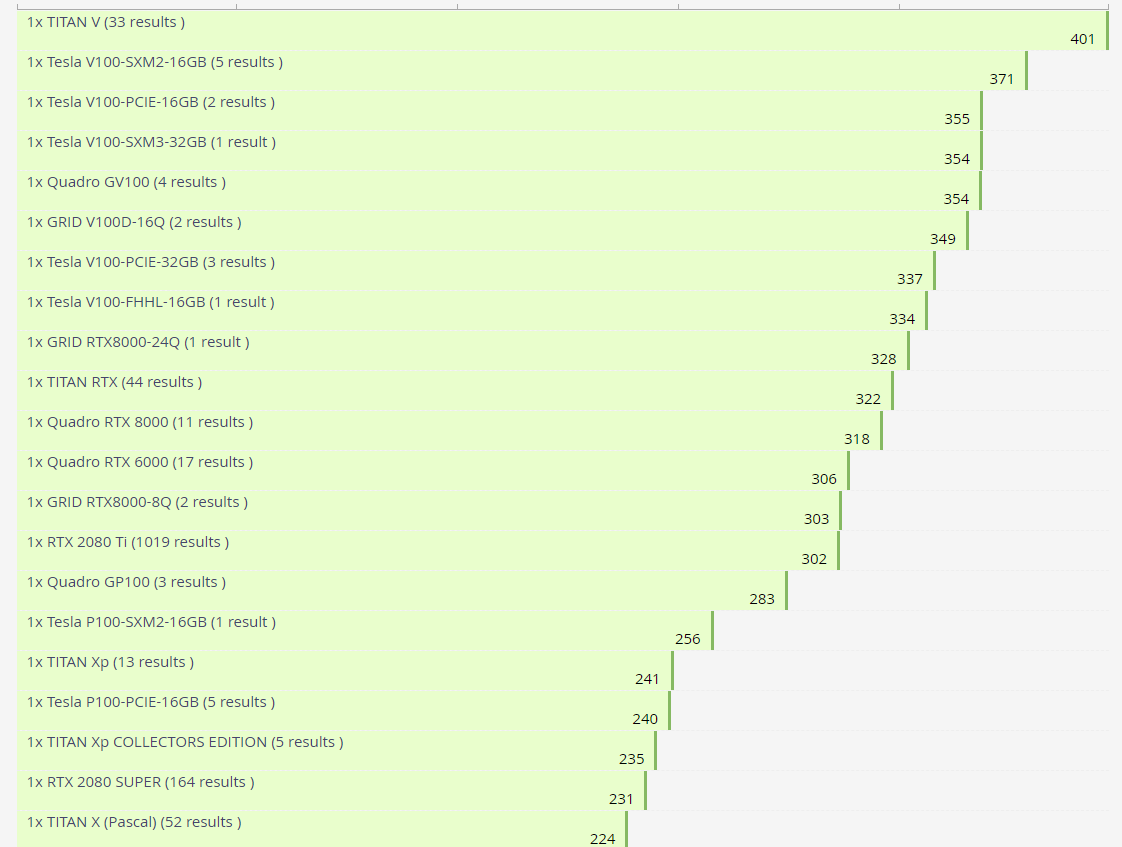
A100 موفق شده امتیاز 446 را ثبت نماید. ما مطمئن نیستیم که دقیقا کدام نتایج با A100 مقایسه شدهاند اما سریعترین کارت گرافیک بر پایه Turing در OctaneBench مدل GRID RTX 8000 میباشد که امتیاز 328 را کسب میکند. مدلهای بر پایه Volta یعنی Tesla V100 و TITAN V و Quadro GV100 همچنان عملکرد بسیار خوبی در مقایسه با Ampere از خود نشان میدهند جایی که 33 الی 11 درصد کاهش کارایی نسبت به A100 خواهند داشت.
| A100 PCIe | A100 SXM | Tesla V100s | Tesla V100 | Tesla P100 | |
| پردازنده گرافیکی | 7 نانومتری GA100 | 7 نانومتری GA100 | 12 نانومتری GV100 | 12 نانومتری GV100 | 16 نانومتری GP100 |
| ابعاد die | 826 میلیمتر مربع | 826 میلیمتر مربع | 815 میلیمتر مربع | 815 میلیمتر مربع | 610 میلیمتر مربع |
| تعداد ترانزیستور | 54 میلیارد | 54 میلیارد | 21.1 میلیارد | 21.1 میلیارد | 15.3 میلیارد |
| تعداد SM | 108 | 108 | 80 | 80 | 56 |
| تعداد هسته CUDA | 6912 | 6912 | 5120 | 5120 | 3840 |
| تعداد هسته Tensor | 432 | 432 | 640 | 640 | ندارد |
| عملکرد FP16 | 39 ترافلاپ | 39 ترافلاپ | 32.8 ترافلاپ | 31.4 ترافلاپ | 21.2 ترافلاپ |
| عملکرد FP32 | 19.5 ترافلاپ | 19.5 ترافلاپ | 16.4 ترافلاپ | 15.7 ترافلاپ | 10.6 ترافلاپ |
| عملکرد FP64 | 9.7 ترافلاپ | 9.7 ترافلاپ | 8.8 ترافلاپ | 7.8 ترافلاپ | 5.3 ترافلاپ |
| فرکانس بوست | 1410 مگاهرتز | 1410 مگاهرتز | 1601 مگاهرتز | 1533 مگاهرتز | 1480 مگاهرتز |
| حداکثر پهنای باند حافظه | 1536 گیگابایت بر ثانیه | 1134 گیگابایت بر ثانیه | 1134 گیگابایت بر ثانیه | 900 گیگابایت بر ثانیه | 721 گیگابایت بر ثانیه |
| فرکانس موثر حافظه | نامشخص | 2430 مگاهرتز | 2214 مگاهرتز | 1760 مگاهرتز | 1408 مگاهرتز |
| پیکربندی حافظه | 40 گیگابایت HBM2e | 40 گیگابایت HBM2e | 32 گیگابایت HBM2e | 16 / 32 گیگابایت HBM2e | 16 گیگابایت HBM2e |
| گذرگاه حافظه | 5120 بیت | 5120 بیت | 4096 بیت | 4096 بیت | 4096 بیت |
| توان حرارتی | 250 وات | 400 وات | 250 وات | 300 وات | 300 وات |
| فرم فاکتور | PCI Express 4.0 | SXM4 | PCI Express 3.0 | SXM2 / PCI Express 3.0 | SXM |
بیشتر بخوانید: ساخت سریعترین ابرکامپیوتر AI توسط NVIDIA در دانشگاه فلوریدا


















دیدگاهتان را بنویسید