



شتابدهندههای هوش مصنوعی NVIDIA HGX H200 با استفاده از الگوریتم مدوسا توانستند به پیشرفت چشمگیری در پردازش و استنتاج مدل Llama 3.1 دست یابند. نوآوری انویدیا در اکوسیستم نرمافزاری خود ادامه دارد و با کمک مدوسا، به بهبود عملکرد دست یافته است. عملکرد الگوریتم جدید مدوسا انویدیا نسبت به مدلهای قبلی سرعت و قدرت بیشتری به همراه دارد.
با گسترش مدلهای زبانی بزرگ (LLM) و افزایش پیچیدگی آنها، استفاده از پردازشهای چندگرافیکی (Multi-GPU) برای ارائه تاخیر کمتر و بازدهی بیشتر در کاربردهای هوش مصنوعی بلادرنگ ضروری شده است.
در سیستمهای چندگرافیکی، عملکرد به توانایی پردازش همزمان درخواستها با استفاده از چندین پردازنده گرافیکی وابسته است. این پردازندهها بهعنوان یک واحد قدرتمند عمل میکنند، با ارتباط فوقسریع بین GPUها و استفاده از نرمافزارهای پیشرفته که توانایی بهرهبرداری کامل از ظرفیت چند GPU را دارند. این کار به کمک تکنیکهایی مثل (موازیسازی تنسور) و الگوریتمهایی مانند رمزگشایی احتمالی انجام میشود که با آن میتوان تأخیر تولید توکنها را بهبود بخشید و تجربه کاربری را روانتر کرد.

برای پردازش سریع Llama 3.1، سیستمهای ابری میتوانند از یک سرور NVIDIA HGX H200 استفاده کنند. هر سرور شامل هشت پردازنده گرافیکی H200 Tensor Core و چهار تراشه NVLink Switch است. این پردازندهها میتوانند با پهنای باند کامل 900 گیگابایت بر ثانیه به یکدیگر متصل شوند. این پهنای باند بالا مانع از ایجاد گلوگاههای ارتباطی بین پردازندهها در استفادههای تعاملی میشود.
کتابخانه TensorRT-LLM و نقش آن در بهبود عملکرد
برای بهینهسازی الگوریتمهای مختلف بر روی سیستمهای NVIDIA H200 HGX، انویدیا از کتابخانه متنباز TensorRT-LLM استفاده میکند. این کتابخانه با استفاده از تکنیکهای پیشرفته مانند موازیسازی تنسور و رمزگشایی احتمالی، عملکرد بهتری در استنتاج مدلهای زبانی بزرگ به نمایش میگذارد.
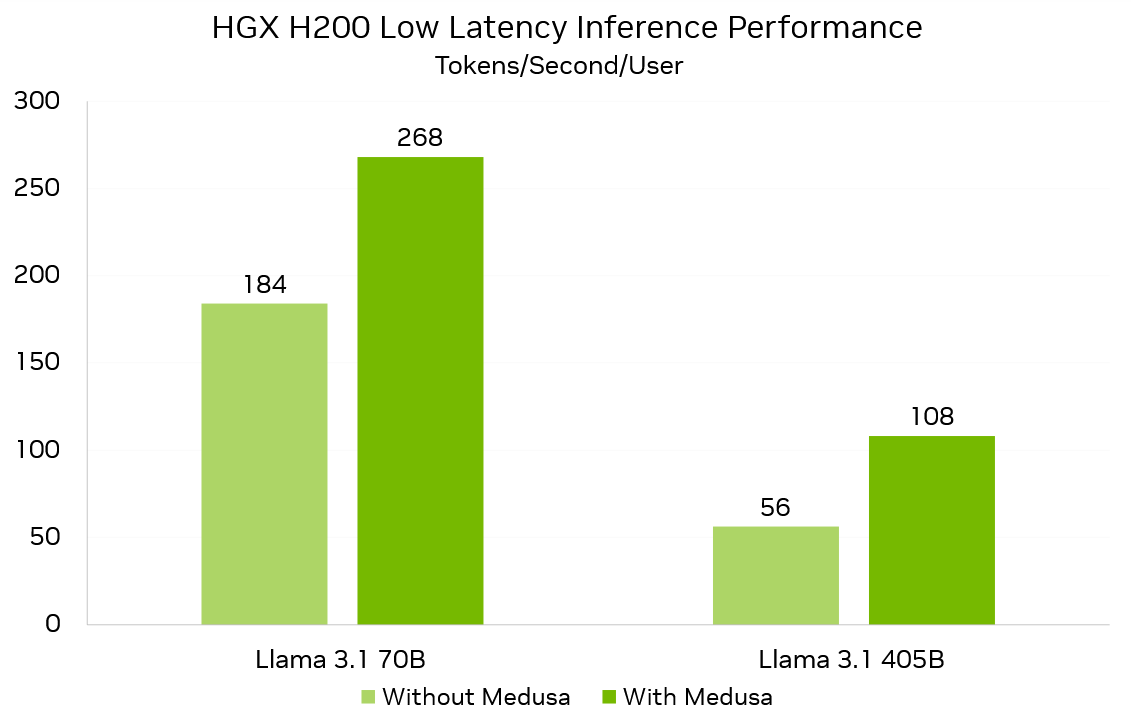
بهینهسازیهای آینده در TensorRT-LLM شامل بهبود الگوریتم رمزگشایی احتمالی مدوسا است که تاخیر استنتاج را در مدل Llama 3.1 به حداقل میرساند. این الگوریتم میتواند در مدل 70 میلیارد پارامتری Llama 3.1، 268 توکن در ثانیه و در مدل 405 میلیارد پارامتری، 108 توکن در ثانیه برای هر کاربر تولید کند.
مدوسا و افزایش 1.9 برابری سرعت تولید توکن
مدلهای زبانی بزرگ که بر پایه معماری ترنسفورمر عمل میکنند، خودبازگشتی هستند؛ یعنی توکنها باید به ترتیب و بهصورت پشتسرهم تولید شوند، که این مسئله سرعت تولید توکن در هر مرحله را محدود میکند. به طور معمول، سرعت تولید توکن به توانایی بارگذاری وزنهای مدل در حافظه وابسته است. این امر میتواند موجب شود که از ظرفیت پردازندههای قدرتمند H200 بهطور کامل استفاده نشود.
رمزگشایی احتمالی روشی است که با استفاده از یک (مدل پیشنویس)، چندین توکن بعدی را پیشبینی میکند. سپس مدل هدف این توکنها را بهصورت گروهی تولید کرده و آنها را با توکن بعدی بهصورت موازی بررسی میکند. این فرآیند موجب میشود که از منابع پردازشی GPU بهینهتر استفاده شود و اگر توکنهای پیشبینیشده توسط مدل اصلی پذیرفته شوند، در هر مرحله چندین توکن تولید شده و بهطور قابلتوجهی سرعت افزایش مییابد.
مدوسا یک الگوریتم پیشرفته رمزگشایی احتمالی است که برخلاف دیگر روشها از همان مدل اصلی بهعنوان مدل پیشنویس استفاده میکند. این کار باعث کاهش پیچیدگیهای سیستم و اختلافات توزیعی ناشی از استفاده از مدلهای پیشنویس جداگانه میشود. مدوسا از (هدهای رمزگشایی) استفاده میکند که این هدها توکنهای بعدی را پیشبینی کرده و هر هد مدوسا توزیع مربوط به توکنهای بعدی را ارائه میدهد.
با کمک مدوسا، سیستم NVIDIA HGX H200 میتواند برای مدل 70 میلیارد پارامتری Llama 3.1، 268 توکن در ثانیه و برای مدل 405 میلیارد پارامتری، 108 توکن در ثانیه برای هر کاربر تولید کند. این نرخ در مقایسه با سیستمهای بدون مدوسا، به ترتیب 1.5 و 1.9 برابر سریعتر است. اگرچه نرخ پذیرش توکنهای تولیدشده توسط مدوسا در وظایف مختلف متفاوت است، اما عملکرد کلی آن در طیف گستردهای از وظایف اثبات شده است.
هدهای مدوسا برای هر دو مدل Llama 3.1 70B و 405B با استفاده از بهینهساز مدل TensorRT و چارچوب NeMo آموزش داده شدهاند. این فرآیند با یک مدل پشتیبانی ثابت انجام شده است که به حفظ دقت مدل اصلی در هنگام استفاده از مدوسا کمک میکند.
نوآوری بیپایان انویدیا در تمامی سطوح فناوری
سیستمهای NVIDIA HGX H200 بههمراه NVLink Switch و TensorRT-LLM در حال حاضر عملکرد بینظیری در استنتاج بلادرنگ مدلهای پیچیده و پرکاربرد ارائه میدهند. انویدیا همچنان به بهبود تجربه کاربری و کاهش هزینههای استنتاج با نوآوریهای مداوم در تمامی سطوح فناوری از جمله تراشهها، سیستمها، کتابخانههای نرمافزاری و الگوریتمها ادامه میدهد.
مطالب مرتبط:


















دیدگاهتان را بنویسید