



گوگل نسخه کامل مدل Gemma 3n را از خانواده مدلهای هوش مصنوعی Gemma 3 منتشر کرد. این مدل که نخستینبار در ماه مه معرفی شد، برای استفاده روی دستگاه طراحی و بهینه شده و چندین بهبود مبتنی بر معماری را در خود جای داده است. نکته قابل توجه اینکه این مدل زبانی بزرگ (LLM) تنها با 2 گیگابایت رم بهصورت محلی اجرا میشود؛ به این معنا که حتی در گوشیهای هوشمندی که از پردازنده مجهز به قابلیت هوش مصنوعی برخوردار باشند، قابل استفاده است.
جزئیات مدل هوش مصنوعی Gemma 3n گوگل
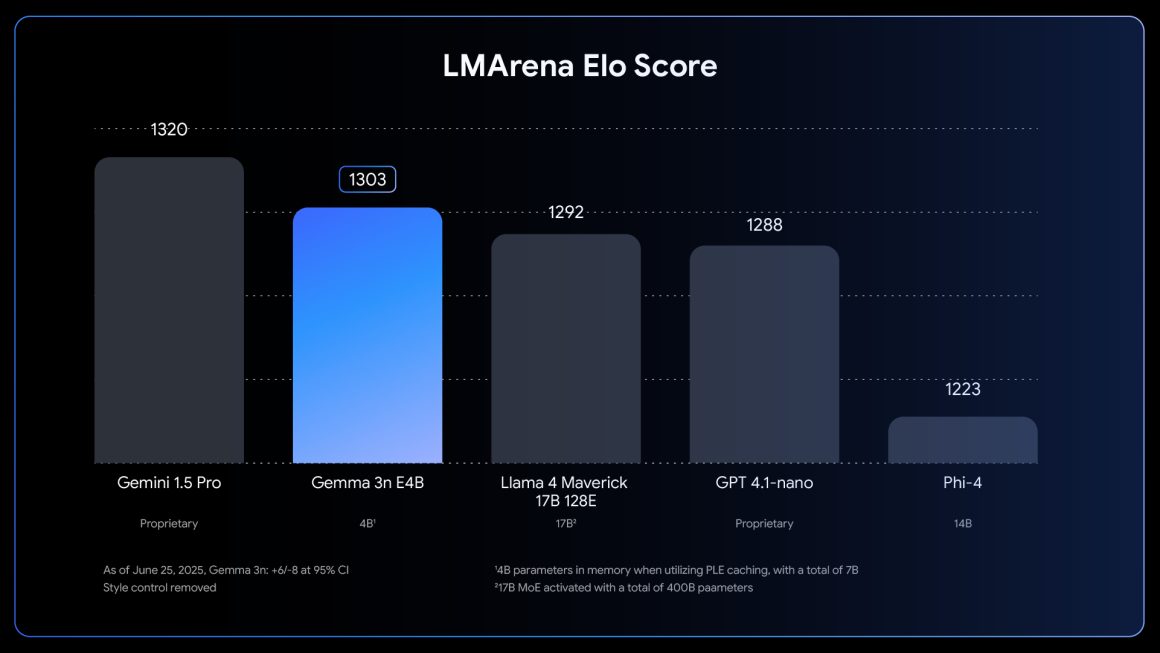
گوگل در وبلاگ رسمی خود از عرضه نسخه کامل Gemma 3n خبر داد. این مدل پس از معرفی مدلهای Gemma 3 و GemmaSign به خانواده Gemmaverse پیوسته است. با توجه به متنباز بودن آن، وزن مدل و مستندات فنی نیز در اختیار جامعه توسعهدهندگان قرار گرفته است. این مدل با مجوز متنباز Gemma منتشر شده که امکان استفاده در پروژههای دانشگاهی و تجاری را فراهم میکند. Gemma 3n یک مدل هوش مصنوعی چندوجهی محسوب میشود؛ از ورودیهای تصویری، صوتی، ویدیویی و متنی بهصورت بومی پشتیبانی میکند، اما تنها خروجی متنی تولید مینماید. همچنین بهعنوان یک مدل چندزبانه، از 140 زبان برای متن و 35 زبان در حالت چندوجهی پشتیبانی میکند.
گوگل اعلام کرده که مدل Gemma 3n با معماری «اول موبایل» طراحی شده و بر پایه ساختار Matryoshka Transformer یا MatFormer توسعه یافته است. این ساختار که نام آن برگرفته از عروسکهای تودرتوی روسی است، شامل ترنسفورمرهای تودرتو میشود که یکی درون دیگری قرار میگیرد. چنین معماریای روشی خاص برای آموزش مدلهای هوش مصنوعی با اندازههای مختلف پارامتر ارائه میدهد. مدل Gemma 3n در دو اندازه E2B و E4B ارائه شده که مخفف “پارامترهای موثر” است؛ به این معنا که با وجود اندازه پنج میلیارد و هشت میلیارد پارامتر، تنها دو و چهار میلیارد پارامتر فعال میماند.
این عملکرد با استفاده از روشی به نام Per-Layer Embeddings (PLE) ممکن شده است؛ در این روش فقط پارامترهای ضروری در حافظه سریع (VRAM) بارگذاری میشود و باقی پارامترها در لایههای اضافی قرار میگیرند و توسط پردازنده مرکزی پردازش میشوند. در سیستم MatFormer، نسخه E4B مدل E2B را درون خود جای میدهد و هنگام آموزش مدل بزرگتر، نسخه کوچکتر نیز همزمان آموزش میبیند. این ویژگی به کاربران امکان میدهد بسته به نیاز، از E4B برای عملیات پیشرفته یا از E2B برای خروجی سریعتر استفاده کنند؛ بدون آنکه تفاوت محسوسی در کیفیت پردازش یا خروجی احساس شود.
گوگل به توسعهدهندگان اجازه داده مدلهایی با اندازه سفارشی ایجاد کنند؛ این قابلیت با تغییر بخشهایی از ساختار داخلی مدل فراهم شده است. برای این منظور، ابزار MatFormer Lab عرضه شده که امکان آزمایش ترکیبهای مختلف را جهت یافتن اندازه مناسب مدل فراهم میسازد.


دسترسی و اجرای مستقیم در فضای ابری
در حال حاضر مدل Gemma 3n از طریق فهرستهای Hugging Face و Kaggle گوگل قابل دانلود است. کاربران همچنین میتوانند با مراجعه به Google AI Studio این مدل را امتحان کنند. شایان ذکر است که مدلهای Gemma را میتوان بهطور مستقیم از طریق AI Studio در Cloud Run نیز اجرا کرد.

















دیدگاهتان را بنویسید