



سرانجام معرفی Nvidia Ampere GA100 صورت پذیرفت. تیم سبز به شکل رسمی پردهها را کنار زده تا قدرتمندترین و بزرگترین گرافیک حال حاضر یعنی مدل 7 نانومتری Ampere را رونمایی کند. اولین محصولی که از معماری جدید Ampere بهره میبرد یک گرافیک با نام GA100 خواهد بود که در حال حاضر بزرگترین گرافیک تولید شده با فناوری 7 نانومتری TSMC میباشد. اجازه دهید با معرفی Nvidia Ampere GA100 نگاهی هر چند کوتاه به گرافیک GA100، معماری Ampere و اولین محصولات آن بیاندازیم.
معرفی Nvidia Ampere GA100 به شکل رسمی
گرافیک Ampere GA100 با فاصله بسیار بزرگترین طراحی یک چیپ گرافیکی 7 نانومتریست. این گرافیک به شکل کامل برای بازار HPC طراحی شده تا اموری مانند تحقیقات علمی، هوش مصنوعی و شبکههای عصبی عمیق را پوشش دهد. مشخصات و محصولات زیادی وجود دارند که ما به برخی از آنها خواهیم پرداخت.


در ابتدا ما گرافیک Nvidia Ampere GA100 را در فرم فاکتورهای مختلف داریم. از یک کارت کوچک ماژولار تا یک کارت گرافیک PCI Express 4.0 کامل. این گرافیک همچنین در پیکربندیهای مختلفی عرضه میشود اما مدلی که انویدیا روی آن مانور بیشتری داده Tesla A100 حاضر در سیستمهای DGX A100 و HGX A100 خواهد بود.
مشخصات گرافیک 7 نانومتری Ampere GA100
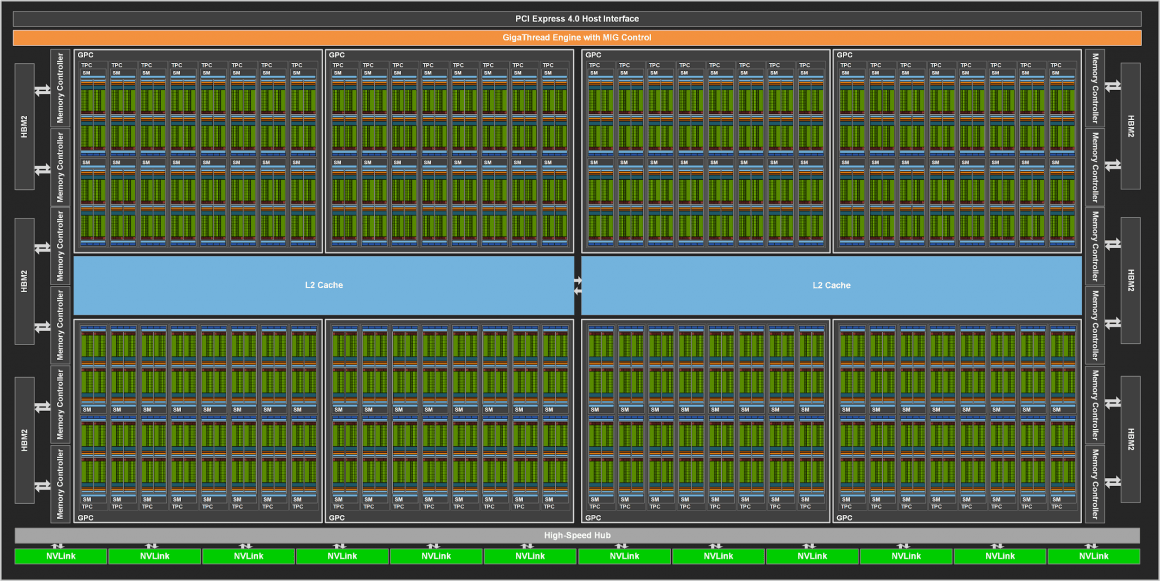
زمانی که به مشخصات اصلی نگاه میکنیم، گرافیک Ampere GA100 انویدیا یک هیولای افسار گسیخته به نظر میرسد. ابعاد چیپ (die) آن بالغ بر 826 میلیمتر مربع خواهد بود که حتی از Volta GV100 با 815 میلیمتر مربع نیز بزرگتر است. این گرافیک همچنین بیش از دو برابر ترانزیستور بیشتری در اختیار دارد، 54 میلیارد در برابر 21.1 میلیارد که واقعا خارق العاده است. با توجه به ابعاد die و تعداد ترانزیستور باید بگوییم Ampere GA100 متراکمترین گرافیک توسعه یافته تا به امروز میباشد.
محصولاتی با چیپ کامل Nvidia Ampere GA100
- 8GPC و 8TOC/GPC و 2SM/TPC و 16SM/GPC و 128SM به ازای هر چیپ کامل
- 64FP32 CUDA Cores/SM و 8192 هسته FP32 CUDA برای هر چیپ کامل
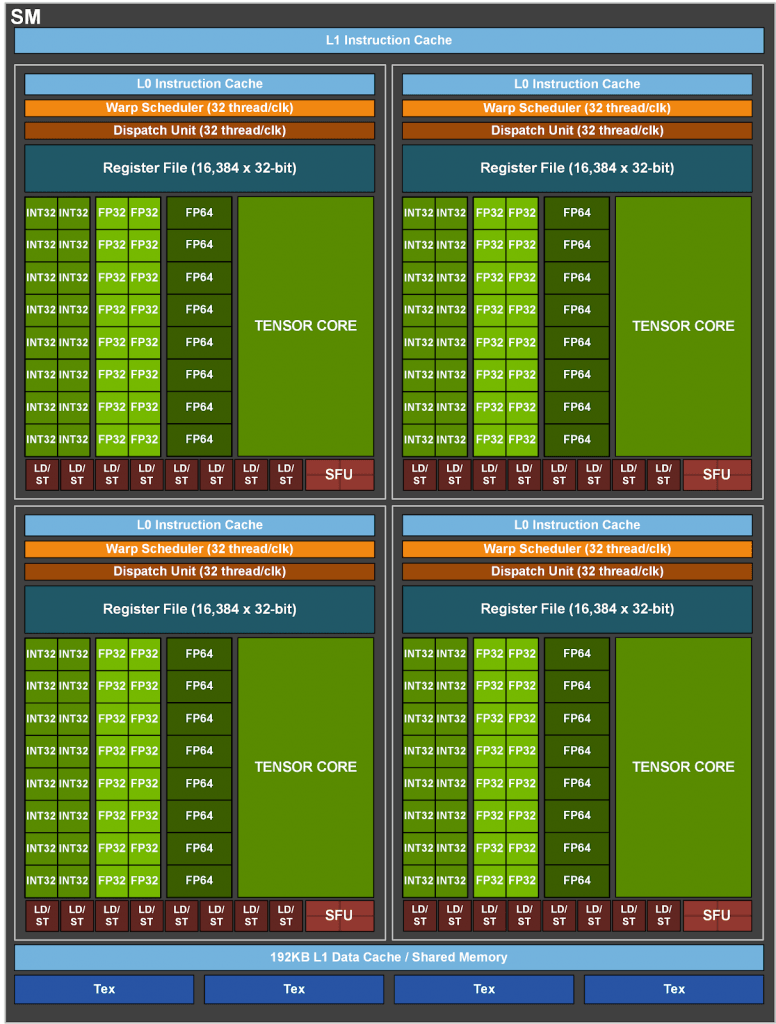
- چهار هسته Tensor به ازای هر SM، تا 512 هسته نسل سوم Tenosr برای هر چیپ کامل
- 6 حافظه HBM2، تا 12 کنترلر حافظه 512 بیتی
محصولاتی با تعبیه A100 Tensor Core از Nvidia Ampere GA100
- 7GPC و 7 یا 8 TOC/GPC و 2SM/TPC و 16SM/GPC و 108SM
- 64FP32 CUDA Cores/SM و 6912 هسته FP32 CUDA برای هر چیپ
- چهار هسته Tensor به ازای هر SM، تا 432 هسته نسل سوم Tenosr برای هر چیپ
- 5 حافظه HBM2، تا 10 کنترلر حافظه 512 بیتی
در حالی که Tesla A100 از نسخه تقلیل یافته چیپ گرافیکی به علت بازده فعلی فناوری 7 نانومتر بهره میبرد اما هنوز به اندازهای فوق العاده هست تا آن را یک سوپر گرافیک بنامیم. در ابتدا اما ما به نسخه کامل (یا اصطلاحا Full Fat) گرافیک Nvidia Ampere GA100 نگاهی خواهیم انداخت.


حضور 128 واحد SM با 8192 هسته CUDA باعث شده تا GA100 به واقع از نظر تعداد هسته هم بزرگترین گرافیک لقب گیرد. 8192 هسته FP32، بالغ بر 4096 هسته FP64 و 512 هسته Tensor را نیز باید به این مجموعه اضافه کنیم. در جمع 8 خوشه پردازش گرافیکی در این چیپ به چشم میخورد که هر کدام 16 واحد SM و 8 TPC را در خود جای دادهاند. گرافیک GA100 توان حرارتی 400 واتی خواهد داشت، البته در نمونه Tesla A100.
باقی مشخصات این گرافیک شامل رابط عظیم 6144 بیت که تا 48 گیگابایت حافظه HBM2e را در شش چیپ HBM2 تعبیه شده در کنار پردازنده گرافیکی پشتیبانی میکند، میباشد. هر پشته حجم 2 گیگابایت حافظه ویدیویی را فراهم میکند تا به 48 گیگابایت حافظه نهایی برسیم. این یعنی شما به پشتههای چهارتایی نیاز دارید، هر پشته چهارتایی حجمی 8 گیگابایتی خواهد داشت و 6 عدد از آنها برابر با ظرفیت 48 گیگابایتی میباشد. ادعا شده که این حافظه به ازای هر پین بیش از 2.0 گیگابیت سرعت خواهد داشت و این یعنی پهنای باندی در حدود 1.6 ترابایت بر ثانیه.
در معرفی Nvidia Ampere GA100 مشخص شد گرافیکهای Ampere البته با پیکربندی حافظه HBM متفاوتی راهی بازار خواهند شد که حداکثر 48 گیگابایت ظرفیت دارند مگر آن که انویدیا تصمیم به استفاده از نمونههای بهتر مانند 6-hi و 8-hi در آینده داشته باشد که به 72 و حتی 96 گیگابایت حجم حافظه خواهیم رسید. Tesla V100S نیز قبلا ظرفیت حافظه HBM را به دو برابر Tesla V100 یعنی 32 گیگابایت نسبت به 16 گیگابایت افزایش داده بود، بنابراین برای تیم سبز چنین کاری کاملا امکان پذیر خواهد بود.
شتاب دهنده Nvidia Tesla A100
با معرفی Nvidia Ampere GA100 و البته مرور مشخصات نسخه Full Fat این گرافیک حالا اجازه دهید درباره شتاب دهنده Tesla A100 صحبت کنیم. این شتاب دهنده از نسخه تقلیل یافته پردازنده GA100 بهره میبرد که تنها 108 واحد SM و 6912 هسته FP32، تقریبا 3456 هسته FP64 و همچنین 432 هسته Tensor را در اختیار دارد. این کارت با رابط حافظه 5120 بیتی و حداکثر 40 گیگابایت حافظه HBM2 عرضه میشود. نکته جالب در مورد حجم حافظه 40 گیگابایتی به طراحی 5-hi اشاره دارد که چندان منطقی نیست پس احتمالا از طراحی 6-hi با برخی چیپهای غیر فعال شده برخوردار گشته.


Nvidia Ampere Tesla A100 از توان حرارتی 400 وات (همانطور که گفته شده) یعنی 100 وات بیشتر از واحد ماژولار Tesla V100 بهره میبرد. نسخه PCIe البته با توان حرارتی کمتر 300 وات همراه شده اما از فرکانس پایینتری برخوردار است. بُرد ماژولار یا Mezzanine از رابط گرافیک به گرافیک از طریق سوییچهای جدید NVLINK بهره مند شده که اینترکانکت گرافیک به گرافیک تا 600 گیگابیت بر ثانیه و 4.8 ترابیت بر ثانیه کانال دو طرفه را فراهم میکند. نمونه PCIe از سوییچ Mellanox بهره گرفته و همچنین دو ارتباط NVLINK نسل بعدی و دو پورت EDR در اختیار دارد.
| کارت گرافیکهای Nvidia Tesla | Tesla K40 PCI-Express | Tesla M40 PCI-Express | Tesla P100 PCI-Express | Tesla P100 SXM2 | Tesla V100 SXM2 | Tesla V100S PCIe | Tesla A100 SXM4 |
| پردازنده گرافیکی | GK110 Kepler | GM200 Maxwell | GP100 Pascal | GP100 Pascal | GV100 Volta | GV100 Volta | GA100 Ampere |
| فناوری ساخت | 28 نانومتر | 28 نانومتر | 16 نانومتر | 16 نانومتر | 12 نانومتر | 12 نانومتر | 7 نانومتر |
| تعداد ترانزیستور | 7.1 میلیارد | 8 میلیارد | 15.3 میلیارد | 15.3 میلیارد | 21.1 میلیارد | 21.1 میلیارد | 54.2 میلیارد |
| ابعاد چیپ | 551 میلیمتر مربع | 601 میلیمتر مربع | 610 میلیمتر مربع | 610 میلیمتر مربع | 815 میلیمتر مربع | 815 میلیمتر مربع | 826 میلیمتر مربع |
| تعداد SM | 15 | 24 | 56 | 56 | 80 | 80 | 108 |
| تعداد TPC | 15 | 24 | 28 | 28 | 40 | 40 | 54 |
| تعداد هسته FP32 CUDA به ازای هر SM | 192 | 128 | 64 | 64 | 64 | 64 | 64 |
| تعداد هسته FP64 CUDA به ازای هر SM | 64 | 4 | 32 | 32 | 32 | 32 | 32 |
| تعداد هسته FP32 CUDA | 2880 | 3072 | 3584 | 3584 | 5120 | 5120 | 6912 |
| تعداد هسته FP64 CUDA | 960 | 96 | 1792 | 1792 | 2560 | 2560 | 3456 |
| تعداد هسته Tensor | ندارد | ندارد | ندارد | ندارد | 640 | 640 | 432 |
| تعداد واحد بافت | 240 | 192 | 224 | 224 | 320 | 320 | 432 |
| فرکانس پایه | 745 مگاهرتز | 948 مگاهرتز | 1190 مگاهرتز | 1328 مگاهرتز | 1297 مگاهرتز | نامشخص | نامشخص |
| فرکانس بوست | 875 مگاهرتز | 1114 مگاهرتز | 1329 مگاهرتز | 1480 مگاهرتز | 1530 مگاهرتز | 1601 مگاهرتز | 1410 مگاهرتز |
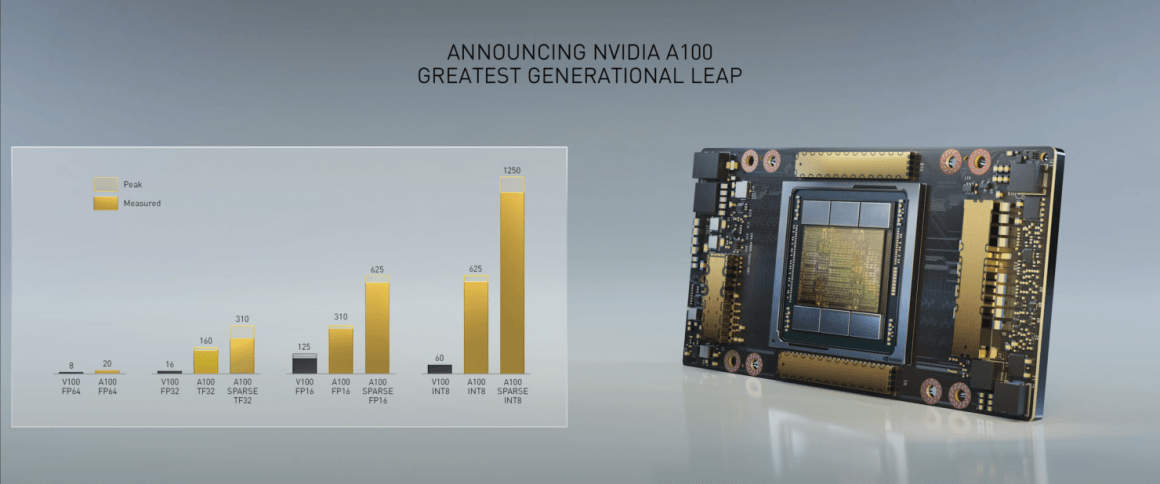
| عملکرد در هوش مصنوعی و شبکه عصبی عمیق | ندارد | ندارد | ندارد | ندارد | 125 TOPs | 130 TOPs | 1248 TOPs 2496 TOPs با Sparsity |
| محاسبات FP16 | ندارد | ندارد | 18.7 ترافلاپ | 21.2 ترافلاپ | 30.4 ترافلاپ | 32.8 ترافلاپ | 312 ترافلاپ 624 ترافلاپ با Sparsity |
| محاسبات FP32 | 5.04 ترافلاپ | 6.8 ترافلاپ | 10.0 ترافلاپ | 10.6 ترافلاپ | 15.7 ترافلاپ | 16.4 ترافلاپ | 156 ترافلاپ 19.5 ترافلاپ استاندارد |
| محاسبات FP64 | 1.68 ترافلاپ | 0.2 ترافلاپ | 4.7 ترافلاپ | 5.30 ترافلاپ | 7.80 ترافلاپ | 8.2 ترافلاپ | 19.5 ترافلاپ 9.7 ترافلاپ استاندارد |
| رابط حافظه | 384 بیت | 384 بیت | 4096 بیت | 4096 بیت | 4096 بیت | 4096 بیت | 6144 بیت |
| حجم حافظه | 12 گیگابایت GDDR5 288 گیگابایت بر ثانیه | 24 گیگابایت GDDR5 288 گیگابایت بر ثانیه | 16 گیگابایت HBM2 732 گیگابایت بر ثانیه 12 گیگابایت HBM2 549 گیگابایت بر ثانیه | 16 گیگابایت HBM2 732 گیگابایت بر ثانیه | 16 گیگابایت HBM2 900 گیگابایت بر ثانیه | 16 گیگابایت HBM2 1134 گیگابایت بر ثانیه | 40 گیگابایت HBM2 1.6 ترابایت بر ثانیه |
| حجم حافظه کش سطح دو | 1536 کیلوبایت | 3072 کیلوبایت | 4096 کیلوبایت | 4096 کیلوبایت | 6144 کیلوبایت | 6144 کیلوبایت | 40960 کیلوبایت |
| توان حرارتی | 235 وات | 250 وات | 250 وات | 300 وات | 300 وات | 250 وات | 400 وات |
از نظر کارایی گرافیک Ampere GA100 بالغ بر 1Peta-OPs را فراهم میکند که 20 برابر بهتر از Volta GV100 میباشد. عملکرد دو رقم آن 2.5 برابر بهتر خواهد بود یعنی نزدیک به 19.5 ترافلاپ FP64 زیرا Volta تقریبا 8 ترافلاپ قدرت محاسباتی FP64 در اختیار دارد. این یعنی عملکرد تک رقمی به بیش از 19.5 در میزان استاندارد و به بیش از 156 ترافلاپ در FP32 خواهد رسید که به واقع در دسته HPC نیز خارق العاده است.
سخت افزارهای Nvidia Ampere GA100
با معرفی Nvidia Ampere GA100 این شرکت Tesla V100 را در دو سیستم DGX و HGX خود قرار داده. سیستمهای DGX به شکل خاص روی تحقیقات مربوط به هوش مصنوعی و بارهای کاری HPC متمرکز هستند و سیستمهای HGX نیز مناسب محاسبات ابری و محیط دیتاسنتر خواهند بود. سیستمهای معرفی شده توسط انویدیا شامل نسل سوم DGX A100 و HGX A100 میشود.
شرکای انویدیا همین حالا نیز سرورهای 1U و 2U و 4U و تا 10U خود را معرفی کردهاند. هر سرور تا 8 گرافیک Ampere GA100 یعنی Tesla A100 را شامل میشود که از ارتباط PCIe 4.0 x16 بهره میبرند. یک بُرد HGX A100 با 4 گرافیک نیز در دسترس است که بهبود عملکرد را با قیمت مقرون به صرفهتر فراهم میکند.

مدیر عامل انویدیا Jensen Huang طی روزهای گذشته به نوعی سیستم DGX A100 را به نمایش گذاشته بود اما سرانجام به شکل رسمی از آن رونمایی شد که حداکثر عملکرد 5 پتافلاپ با 8 گرافیک Tesla A100 را فراهم میکند.

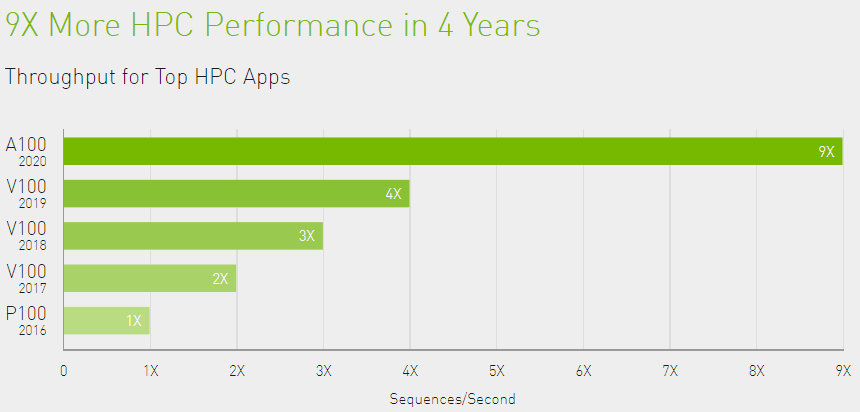
خود این سیستم به تنهایی 20 برابر سریعتر از مدل قبلی DGX بر پایه معماری گرافیکی Volta است. طراحی مرجع شامل 14 گرافیک DGX A100 با یک اینترکانکت 200 گیگابیت بر ثانیهای Mellanox Infiniband میباشد. سیستم DGX A100 با شروع قیمت 199000 دلار همراه بوده و از همین حالا نیز برای سفارش در دسترس است.
بیشتر بخوانید: کارایی چهار برابری معماری Ampere در Ray Tracing و میزان IPC بالاتر از Turing


















آها سری تسلا ، خب ، خیلی خوبه ، خیلی خوبه🙄😴 … هر وقت کارت های گیمینگ مثل 3080 معرفی شد صدام کنین 😂
سلام و عرض ادب به شما آقای کرماجانی
ممنون از مقاله خوبتون.
به نظرم یه ابهاماتی هست که به نظرم باید توضیح داده بشه چون باعث لکنت شده.
این کارت مشخصات فوقالعاده ای داره که ماحصل کاهش لیتوگرافی، HBM2e و تغییرات انویدیا توی معماری و نوع پردازش هاست
پهنای باند حافظه به خاطر نوع VRam افزایش بسیار خوبی داشته.
تعداد ترانزیستورها به لطف ریخته گری tsmc بیش از 2.5 برابر شده.
سیستم تقسیم GPU به تعداد بیشتر و ابعاد کوچکتر برای بهبود کارای در مواقع لزوم ( یه جور hyper Threading ) .
نسل جدید و قدرتمند هسته های tensor که حالا میتونن پردازش هایی با دقت Double Precision انجام بدن و به کمک هسته های FP64 بیان.
و sparsity.
چند مشکل داشتم که امیدوارم پاسخ بدید.
اول درمورد فرمت جدید tensor float 32 که چیزی مابین FP32 ,FP 16 ست . یعنی دارای یه exponent 8 bit (معرف) هست مثله FP32 ولی به اندازه 10bit میتونه توی خودش ذخیره کنه مانند FP16. این فرمت دیتا های 32 بیتی قبول میکنه ولی با دقت 16 بیت یا half precision پردازش میکنه. سوال اینجاست که چرا انویدیا و به تبع اون شما این فرمت رو در مقام مقایسه با FP32 آوردین؟
(از طرفی این فرمت قراره به AI کمک کنه و هوش مصنوعی نیاز به دقت پردازشی 32 نیاز نداره البته تا جایی که سوادم قد میده).
دوم درمورد نسل جدید هسته های تنسور که محاسبات 64 بیتی انجام میدن و قراره به هسته های FP64 کمک کنن تا باعث افزایش کارایی بشه. افزایش حجم پردازش به کمک هسته های تنسور به نظرم باید متغییر باشه و مقدار اون که توی جدول ذکر شده فکر کنم باید مقدار peak یا بیشینه باشه. به عنوان مثال اگه کارت درگیر محاسبات FP64 – FP32 – TF32 به طور همزمان باشه، باتوجه به یکپارچه بودن و کم شدن تعداد tensor core ها در هر SM به نسبت هسته های دیگه، افزایش کارایی خواهیم داشت ولی نه به اندازه ای که در جدول ذکر شده.
لطفا اگه اشتباه میکنم، شما حرفم رو اصلاح کنید.
سوم این بحث تقسیم GPU به ابعاد کوچکتر و تعداد بیشتر یا همون MIG یا دقیقتر Multi-Instance GPU چه زمانی به وقوع میپیونده؟ و اینکه این کار به صورت خودکار از سمت GPU مدیریت میشه یه مثله sparsity از طرف developer ها مدیریت میشه؟
چهارم اینکه اگه میشه توضیح بدید که آیا Sparsity فقط یه بخش نرم افزاریه که به توسعه دهندگان اجازه میده با حذف المان های کم اهمیت باعث سبک تر شدن بار GPU و به دنبال اون افزایش 2 برابری کارایی میشه؟ (همونطور که د جدول بهش اشاره کردید)
پنجم به نظرتون افزایش حجم پردازش FP64 و FP32 به صورت استاندارد با توجه به افزایش قابل توجه هسته های اونها، کم نیست؟ حدود 3 ترافلاپس برای 32 و نصف اون برای 64؟
در آخر هم میخوام دوباره بگم که اگه میشه یه بازنگری اساسی توی ساختار بخش کامنت ها کنید. چون خیلی محدوده و از ورژن قبلش بسیار ضعیفتر
باتشکر از سعه صدر و مقاله خوبتون
سلامت باشید
سلام و عرض ادب.
متشکرم لطف دارید.
والا بنده به اندازه شما و باقی دوستان علم ندارم. هنوز هم فرصت نکردم مطلب انویدیا رو کامل مطالعه کنم، فقط بخشهایی که در این مطلب هست رو به شکل مختصر خوندم.
تقریبا همین سوالات هم برای بنده پیش اومده ولی عرض کردم هنوز فرصت نکردم به شکل دقیقتری مطالعه کنم نطق انویدیا رو.
مورد دوم من همین فکر رو میکنم و حتما انویدیا پیک کارایی رو در حالت بار کاری تنها هستههای Tensor حساب کرده.
در مورد تقسیم پردازنده یا همون MIG که صحبت شده ازش، من هنوز نخوندم که خودکار هست یا خیر اما بعید میدونم. تا جایی که اطلاع دارم انویدیا تنها اعلام کرده میشه یک GPU A100 رو به نهایت هفت پردازنده مستقل تقسیم کرد و به نظرم نمیاد که از سمت خود پردازنده گرافیکی صورت بگیره مگر این که انویدیا از طریق نرم افزارهای خودش این قابلیت رو فعال کنه.
در مورد Sparsity هم مطالعه دقیقی نداشتم اما از شناخت قبلی باید یه قابلیت نرم افزاری یا بهتر بگم یکسری الگوریتم باشند که توسط هوش مصنوعی تاکیدی انویدیا اجرا خواهند شد.
در مورد حجم پردازش FP64 و FP32 هم البته که نظر بنده مهم نیست چون نه دانش لازم رو در اختیار دارم و نه صلاحیتش رو اما افزایش تعداد هستهها در عین کاهش فرکانس صورت گرفته، یعنی نسبت به GV100 ما 200 مگاهرتز کلاک بوست پایینتری داریم (حالا هنوز به شکل دقیق مشخص نیست). یک نکته رو هم بگم ما در جایی مثل معماری GCN افزایش تعداد هستهها رو شاهد بودیم اما به همون میزان افزایش کارایی نداشتیم حالا باز باید صبر کنیم و اطلاعات دقیقتری رو ببینیم.
در مورد بخش کامنتها هم دوستان در حال بررسی و رفع اشکالات و غیره هستند، خیالتون راحت باشه.
ممنون از شما بابت اطلاعات دقیقتون و عذر خواهی میکنم اگر با دانش پایینم پاسخ مناسبی ارائه نکردم.
سلام و درود
اولا بنده باید عذر خواهی کنم که وقت شریف شما رو گرفتم نه شما
استاد گرامی.
مطالب شما رو کم و بیش میبینم و از قلمتون استفاده میکنم و لذت میبرم. استریم انویدیا رو سرسری دیدم نکات جالب توجهی داشت که بعضی هاش رو متوجه نشدم. گفتم از شما کمک بخوام برای درک بهترشون. مثله اینکه شما هم بدلیل کمبود وقت نتونستید مطالعه شون کنید.
پس اگه خدا بخواد منتظر مقاله خوب شما مثله همیشه درباره این موارد باشیم .
بازم عذر میخوام
از همکارن از طرف ما تشکر کنید
سلامت باشید و ایام به کام
خواهش میکنم، بنده وظیفه دارم وقتم رو در اختیار شما قرار بدم. ولی خب بنده بیشتر استفاده میکنم از نظرات شما عزیزان تا یاد بگیرم.
اگر وقت اجازه بده حتما مطلبی رو کار میکنم دربارش اما امیدوارم خودتون فرصت کنید و دقیق مشاهده کنید چون مطلب من مشخصا ایرادات فنی زیادی خواهد داشت.
هر امری بود در خدمت هستم.
به روی چشم.
متشکرم و روزگار خوش
سلام
می دونم اینجا بحث پردازنده نیست اما با شناختی که ازتون دارم خواستم از شما بپرسم.
۱-می دونید که amd در چه وضعیتی قرار داره حالا و اینتل تو نسل دهم برای رقابت محبور به افزایش تعداد هسته و رشته شد. سوالم اینه که اگه الان اینتل مشکل حرارتی نداشت بین مثلا دو مدل 10400 و 3600 یا مثلا 10600k و 3600x کدوم انتخاب می کردید و به چه دلیل؟ قدرت مولتی ترد رایزن ها کمی بالاتر هست و فرضرد بر این بگیرید قدرت سینگل ترد برابر یا با تفاوت ناچیز هست.
۲-ازتون در مورد لینوکس پرسیده بودم به خاطر این بود که تو فروم ها ی سری چیزایی خوندم که بعضی نسخه های لینوکس با رایزن مشکلاتی دارند البته منطورم اون باگ اولیه ی نسل ۳ نیست که سیستم بوت نمی شود باگ رفع شده در هر صورت برای کار با لینوکس و نرم افزار android studio و کلا برای برنامه نویسی نظر شما در مورد رفتن سمت رایزن چی هست؟ من تا حالا ندیدم برنامه نویسی از amd استفاده کنه هرچند الان برای ادیت فیلم و کار با نرم افزار های گرافیکی سمتش میرن که خیلی هم خوبه به نظرم.
این مهمه که تو برنامه نویسی هم از پتانسیل بالای amd استفاده میشه و در عمل هم قدرت بالاتری ارائه میده یا نه.
ممنون از وقت گذاشتنتون.
سلام
نمیدونم روی صحبتتون با بنده بود یا استاد کرماجانی
من در حد خودم میگم حالا اگه استاد لازم دونستن اصلاح یا تکمیل کنن
دررابطه با سوال اول باید بگم خرید یه محصول نیاز به روبه روشدن با واقعیات اون داره.اینکه میگید اگه مشکل توان حرارتی چطور میشد به دور از واقعیته. ما در حال حاضر با یه محصول روبرو هستیم که یه پک از نقاط قدرت و ضعفه. که زیاد بودن TDP یکی از اون نقاط منفی بزرگه.
حالا اگه بگیم فرض شما درسته. باید به فاکتور مهم خرید هرچیزی (در اینجا پردازنده) دقت کنیم
استاندارد performace / price که شما بابت هزینه ای که میکنید چقدر کارایی نسیبتون میشه
حالا این کارایی در یک مصول مشخص، ممکنه برای شما و برای من متفاوت باشه
در موضوع پردازنده ها و شرایطی که گفتید برای من به دلیل استفاده تعداد زیادی از نرم افزارها تعداد هسته بالا بیش از فرکانس به کار میاد (البته در تناسب مناسب با فرکانس) به همین دلیل من به سمت AMD میل میکنم.ممکنه برای شما اینطور نباشه.
شما باید بدونید چه کار میخواید انجام بدید بعد بین چند گزینه یکی رو انتخاب کنید (با وجود شرایط یکسان، اعم از میزان مصرف و حرارت و IPC و IPS و قیمت و …)
که در حال حاضر یه چیز انتزاعیه.
در رابطه با سوال دومتون:
این باگ ها و ایرادتی که میگید برای محصولی که تازه وارد بازار شده با یه معماری نوین خیلی عادیه.
یکی از دلایل اینکه اینتل توی بعضی از نرم افزار ها بهتر عمل میکنه بهینه سازی های بسیار زیادیه که توی این 7-8 سال روی توسعه این نرم افزارها شده (این تقریبا 7-8 سال از یه معماری ثابت با بهینه سازی های بعضا جزئی استفاده میکنه) و محصولی که تازه مجوز ورود به بازار رو گرفته کمی طول میکشه تا توسعه دهنده ها ایزارهای خودشون رو با اون اداپته کنن.
درباره نرم افزار android studio و کارایی اون با رایزن ها در سیستم عامل لینوکس یا ویندوز اطلاعات من قدیمیه و دقیق نیست. فقط میتونم بگم تا دو سال پیش که اندروید استدیو برای رایزن ها نسبتا بهینه شد، کاراییشون در لینوکس بیش از ویندوز بود و توی بسیاری از فروم ها ، توسعه دهندگان از کارایی رایزنها راضی بودن. ولی در این زمینه باید از کسی کمک بگیرید که اطلاع بیشتری از اندروید استدیو داشته باشه.
در رابطه با موضوع کلی برنامه نویسی با پلتفرم رایزن، میتونم بگم این قضیه به IDE برمیگرده نه زبان برنامه نویسی (مخصوصا زبان های low level) . در حال حاضر فکر میکنم بهترین IDE های موجود از رایزن ها پشتیبانی و خوب کار میکنن (خودتون برای اطمینان یه دور چک کنید)
امیدوارم کمک کرده باشم
سلامت باشید.
ممنون
خیلی توضیحات کاملی بود.
ممنون
صد در صد یک غوله اما توجه کنید مصرف هم رفته بالا یعنی به نظرم به جایی رسیدیم که دیگه نمیشه صرفا با کم کردن لیتوگرافی قدرت بالا برد و ناچار باید مصرف بالاتر هم لحاظ کنیم
سلام پسر خوب چطوری؟
نکته جالبی گفتی ولی این افزایش TDP برای سیستم یکپارچه datacenter چیز زیادی نیست و به نظرم این قدرت،
ارزش بالا بردن توان مصرفی و حرارتی رو داره.