



شرکت انویدیا اعلام کرد که شتابدهنده TensorRT را به پلتفرم RTX خود اضافه کرده است. با استفاده از TensorRT، کاربران عادی که از کارت گرافیک RTX بهره میبرند میتوانند عملکرد سریعتری را از طریق زیرساخت بهینهشده استنتاج تجربه کنند. با TensorRT، کاربران شاهد افزایش عملکرد تا دو برابر در برنامههای هوش مصنوعی نسبت به DirectML خواهند بود. TensorRT همچنین به صورت بومی توسط Windows ML پشتیبانی میشود و لازم به ذکر است که TensorRT-LLM هماکنون روی ویندوز در دسترس قرار دارد.
افزایش دو برابری شتاب هوش مصنوعی نسبت به DirectML با TensorRT؛ در دسترس برای تمام کارتهای گرافیک RTX
در حال حاضر، توسعهدهندگان نرمافزارهای هوش مصنوعی برای کامپیوتر با دو انتخاب مواجهاند، استفاده از فریمورکهایی با پشتیبانی سختافزاری گسترده اما عملکرد پایینتر، یا بهرهگیری از مسیرهای بهینهشدهای که تنها برخی سختافزارها و مدلها را پوشش میدهند و نیازمند نگهداری چندین مسیر مختلف هستند. Windows ML بهعنوان یک فریمورک جدید برای حل این چالشها طراحی شده است.



Windows ML که بر پایه ONNX Runtime توسعه یافته، بهطور یکپارچه با لایه اجرای هوش مصنوعی بهینهشدهای که توسط هر سازنده سختافزار ارائه و نگهداری میشود، ادغام میشود. برای کارتهای گرافیک GeForce RTX، این فریمورک بهطور خودکار از TensorRT برای RTX بهره میبرد، کتابخانهای که برای استنتاج، عملکرد بالا و استقرار سریع بهینه شده است. در مقایسه با DirectML، TensorRT بیش از 50 درصد عملکرد سریعتر را برای پردازشهای هوش مصنوعی در کامپیوترهای شخصی ارائه میدهد.

مزایای Windows ML برای توسعهدهندگان
Windows ML همچنین مزایای قابل توجهی برای توسعهدهندگان به همراه دارد. این فریمورک میتواند به صورت خودکار سختافزار مناسب برای اجرای هر قابلیت هوش مصنوعی را انتخاب کند و ارائهدهنده اجرای مربوط به آن سختافزار را دانلود نماید؛ بنابراین نیازی به اضافه کردن این فایلها به برنامه نیست. این موضوع به انویدیا اجازه میدهد تا به محض آماده شدن، بهینهسازیهای جدید عملکرد TensorRT را در اختیار کاربران قرار دهد. همچنین به دلیل ساختار مبتنی بر ONNX Runtime، Windows ML با هر مدل ONNX سازگار است.

ویژگیهای جدید TensorRT برای سری RTX
فقط عملکرد، جنبه اصلی TensorRT برای سری RTX نیست. این زیرساخت جدید باعث کاهش 8 برابری حجم فایل کتابخانهها شده است و همچنین بهینهسازیهای لحظهای برای هر کارت گرافیک را به همراه دارد. TensorRT برای RTX در خرداد ماه برای تمام کارتهای گرافیک انویدیا RTX از طریق developer.nvidia.com در دسترس قرار خواهد گرفت.
افزایش عملکرد در نرمافزارهای مختلف
در یکی از اسلایدهای عملکردی، شرکت انویدیا افزایش عملکرد هوش مصنوعی با TensorRT در مقایسه با DirectML را نمایش داده است. در نرمافزار ComfyUI، کاربران میتوانند شاهد افزایش دو برابری عملکرد باشند؛ در حالی که DaVinci Resolve و Vegas Pro افزایش 60 درصدی را ارائه میدهند. این موضوع منجر به زمان اجرای سریعتر هوش مصنوعی و بهبود فرآیندهای کاری میشود و به کارتهای گرافیک RTX و کامپیوترهای RTX اجازه میدهد تا پتانسیل کامل خود را به نمایش بگذارند.
نوآوریهای نرمافزاری جدید انویدیا
نوآوریهای نرمافزاری شرکت انویدیا به همین جا ختم نمیشود؛ چرا که این شرکت بیش از 150 کیت توسعه نرمافزاری هوش مصنوعی را با 5 ادغام جدید ISV که در اردیبهشت ماه ارائه میشوند، پشتیبانی میکند. این موارد شامل موارد زیر هستند:
- LM Studio (با 30 درصد افزایش عملکرد با جدیدترین CUDA)
- Topaz Video AI (شتابدهی ویدیو GenAI با CUDA)
- Bilibili (افکتهای NVIDIA Broadcast)
- AutoDesk VRED (DLSS 4)
- Chaos Enscape (DLSS 4)



معرفی NIM و AI Blueprints جدید
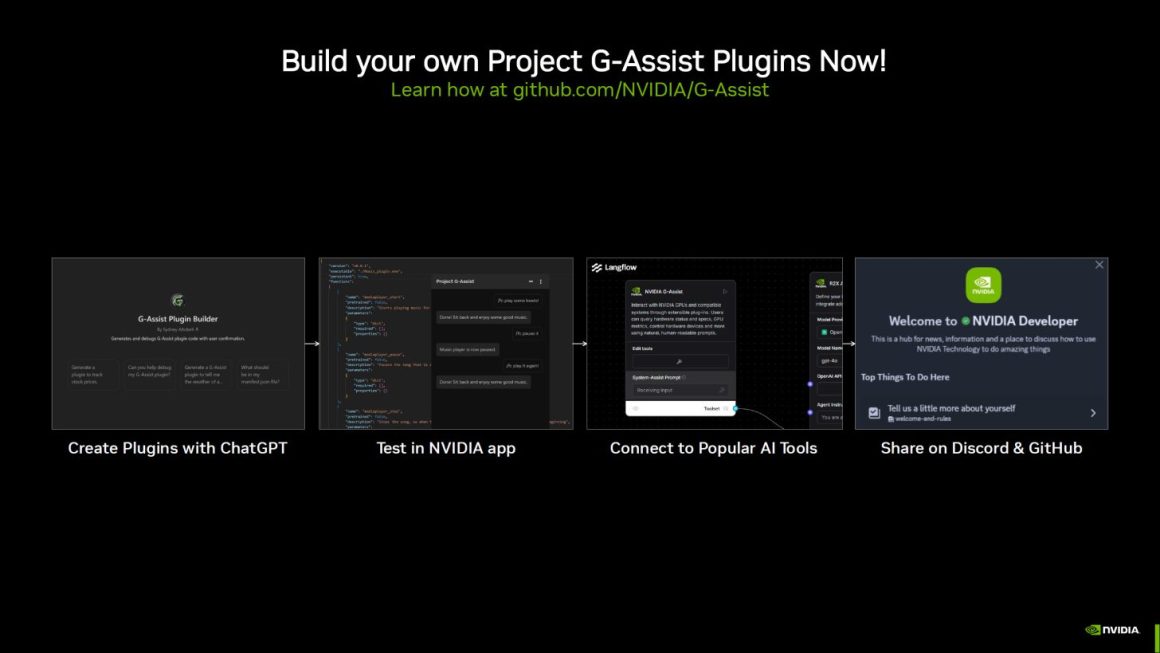
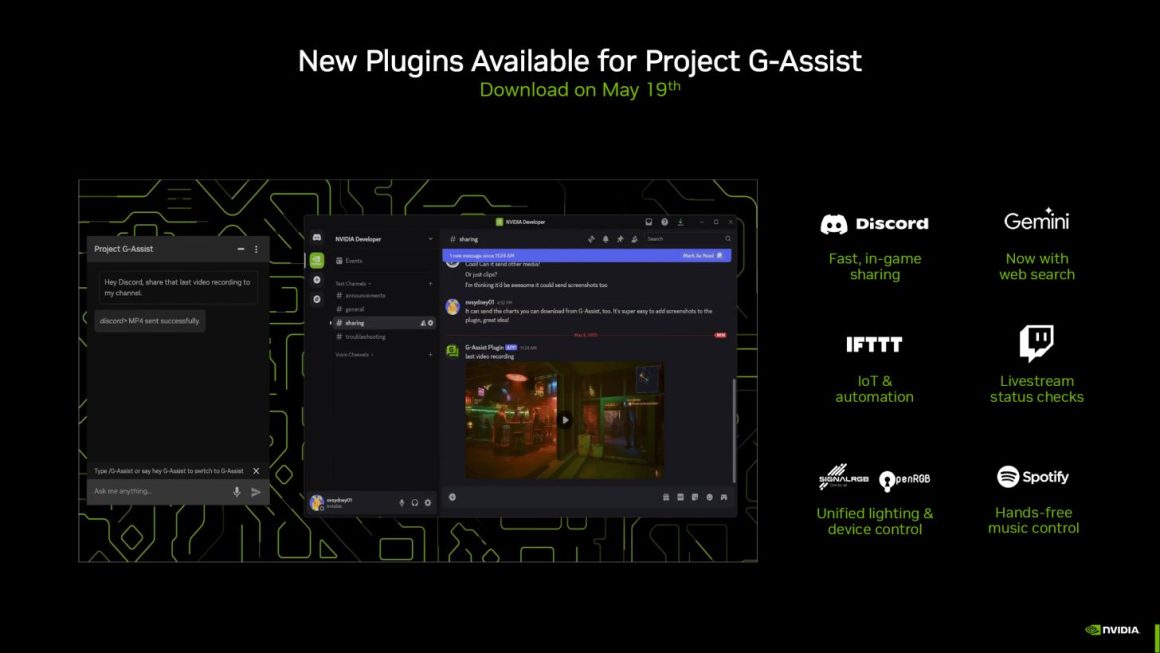
انویدیا همچنین NIM و AI Blueprints جدید را معرفی کرده است که حتی شامل افزونههای جدید برای Project G-Assist مانند Discord، Gemini، IFTTT، Twitch، Spotify و SignalRGB میشود. همچنین کاربران میتوانند افزونههای مخصوص خود را برای Project G-Assist با مراجعه به github.com/NVIDIA/G-Assist ایجاد کنند.
























دیدگاهتان را بنویسید