


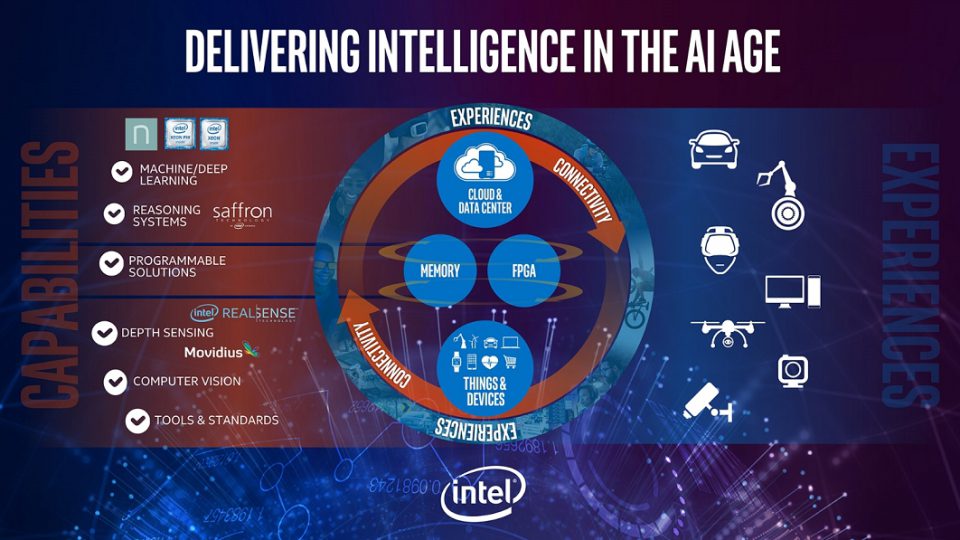
با ظهور یادگیری AI در صنعت، وظیفه بخش سخت افزار است که برای تامین نیازهای پردازشی آن قدم بردارد. کمپانی های Intel، Nvidia و AMD در این حوزه فعال هستند. افزون بر پردازش های مبتنی بر پردازنده گرافیکی (GPU) دو برند تولید کننده پردازنده در جهان، خصوصا اینتل، تولید پردازنده (CPU) های آن را بر عهده دارند. از پردازنده گرفته تا کامپیوتر و ماژول های آماده، سخت افزارهایی است که در این بخش به مرز تولید رسیده اند. اینتل در پروژه هایی همچون معماری Lake Crest chip پردازش های Deep neural network را دنبال کرده و در آنها بسیار موفق ظاهر شد. با توجه به این مسئله اینتل پروژه ای جدید موسوم به Nervana را استارت زده است. این پروژه با میزان بی سابقه ای از تراکم محاسبه در سیلیکون ارائه می شود که حتی از پردازنده های گرافیکی انویدیا و AMD نیز بیشتر است. اینتل در این طرح به پردازش های حوزه DNN (Deep Neural Network) می پردازد و در دو بخش ماژولار و پردازنده فعال می گردد. اینتل مدعی آن شده است که قدرت پردازش های این پلتفرم از پردازش های خام GPU های مرسوم بسیار بیشتر است؛ اما آیا واقعا اینگونه خواهد بود؟ با توجه به مشخصاتی که این شرکت از پروژه Nervana اعلام کرده است، می توان امیدوار بود که اینگونه گردد.

فناوری سیلیکون متغییر با هدف ضرب ماتریس و پیچیدگی بیشتر در پردازش ها در این الگوریتم مورد استفاده قرار گرفته است. تراشه های Lake Crest از پردازنده های Xeon بهره می برند اما کارایی کلی آنها با پردازش های زئون متفاوت است. این سیستم به طور خاص طراحی شده برای افزایش حجم کار AI در یک سرعت بی سابقه است. اینتل از یک معماری پیچیده پردازشی با نام Flexpoint در این پلتفرم استفاده کرده است که در تراشه های Lake Crest تزریق شده است. پس یک تراشه جامع با پردازنده های متفاوت Xeon اما معماری پردازشی متفاوت. همچنین این پلتفرم استفاده از قابلیت های MCM (Multi Chip Module) را افزایش می دهد.
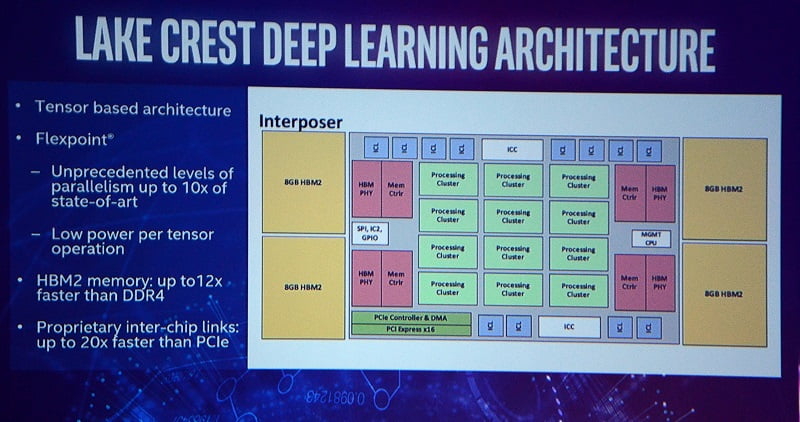
در مجموع 32 گیگابایت حافظه HBM 2 در پشته (Stacks) های 8 گیگابایتی برای آن در نظر گرفته شده است. کلاک هسته به 2.0 گیگاهرتز می رسد و این در حالی است که پهنای باند حافظه نیز 1 ترابایت در ثانیه اعلام شده است. پروژه Nervana در نیمه اول سال 2017 به مرحله آزمایش های نهایی خواهد رسید. این تراشه بسیار مقیاس پذیر تر از موارد گذشته است و 12 لینک دو طرفه با پهنای باند بالا را ارائه می دهد که در مجموع 20 برابر سریعتر از PCI Express است. در نهایت باید گفت که اینتل AI learning را به زودی با درهای جدید پردازش مواجه خواهد کرد. در کسری از زمان پاسخ پردازش های تخصصی را خواهیم گرفت.


















سلام ببخشید دوست عزیز وقتی ایشون اندک شعوری واسه کسانی که کامنتهاشون رو میخونن قائل نیستن… زشت نیست؟
زشته :l
:smiley3 رامین خخخخخ:smiley3:smiley3:smiley3
یه پردازنده 8350 با کارت 460 تو دایرکت ایکس 12 بهتر ازاینه :smiley3
منتظر نظرات کارشناس سایت هستم…..