



در سال 2016، هوش مصنوعی DeepMind ، پی در پی بهترین بازیکنان بازی Go را شکست داد. یک سال بعد، این شرکت پای خود را فراتر گذاشت. این هوش مصنوعی با مشاهده مسابقات آماتور و حرفهای بازی Go آن را آموخت، و به سادگی با بازی در برابر خودش به بازی باستانی تسلط یافت! سپس DeepMind AlphaZero ساخته شد که میتوانست بازیهای Go ، شطرنج و Shogi را با یک الگوریتم واحد بازی کند.
نکته مشترک تمام این هوش مصنوعیها این است که آنها قوانین بازیهایی را که باید در آنها تسلط داشته باشند را از قبل میدانند. اما جدیدترین هوش مصنوعی DeepMind با نام MuZero برای تسلط بر این بازیها نیازی به قواعد بازی، شطرنج، شوگی و غیره ندارد. درعوض، همه آنها را به صورت خودآموز فرا گرفت و به همان اندازه از الگوریتمهای قبلی DeepMind در آنها توانایی دارد.
هوش مصنوعی DeepMind چگونه به این قابلیت دست یافت؟
هوش مصنوعی DeepMind این مشکل را با استفاده از روشی به نام lookahead search برطرف کرده است. با استفاده از این روش، یک الگوریتم حالتهای آینده را برای برنامه ریزی یک اقدام در نظر میگیرد. بهترین راه برای این مورد، فکر کردن در مورد چگونگی انجام یک بازی استراتژیک (مانند شطرنج یا Starcraft II) است. قبل از اقدام، نحوه برخورد حریف را در نظر خواهید گرفت و سعی میکنید بر اساس آن برنامه ریزی کنید. تقریباً به همین ترتیب، هوش مصنوعی که از روش lookahead استفاده میکند، سعی میکند چندین حرکت را از قبل برنامه ریزی کند. حتی با داشتن یک بازی نسبتاً ساده مانند شطرنج، در نظر گرفتن هر حالت احتمالی در آینده غیرممکن است، بنابراین این هوش مصنوعی آنهایی را که به احتمال وقوع بیشتری دارند را در اولویت قرار میدهد.

مشکلات پیش رو
مشكل اين روش اين است كه در بيشتر موقعيتهاي واقعي و حتي بعضي از بازيها، قوانين سادهاي حاكم بر نحوه عمل آنها وجود ندارد. بنابراین برخی از محققان سعی کردهاند با استفاده از رویکردی که میکوشد چگونه یک بازی خاص یا محیط سناریو بر یک نتیجه تأثیر بگذارد و سپس از این دانش برای تهیه برنامه استفاده کنند، مشکل را حل کنند. اشکال این سیستم این است که برخی از دامنهها به قدری پیچیده هستند که مدل سازی هر جنبه را تقریباً غیرممکن میکنند. به عنوان مثال ثابت شده است که این مورد در بیشتر بازیهای آتاری وجود دارد.
حال این هوش مصنوعی (با نام MuZero) به جای مدلسازی همه حالتها، فقط سعی در بررسی آن حالتهایی دارد که برای تصمیم گیری مهم هستند. در واقع این همان کاری است که شما به عنوان یک انسان انجام میدهید. وقتی بیشتر مردم از پنجره بیرون نگاه میکنند و میبینند که ابرهای تیره در افق در حال شکل گیری هستند، عموماً در فکر چیزهایی مانند جبهههای متراکم و فشار قرار نمیگیرند. بلکه به این فکر میکنند که اگر بیرون از خانه رفتند چگونه باید لباس بپوشند تا گرم بمانند. MuZero نیز کاری مشابه انجام میدهد.
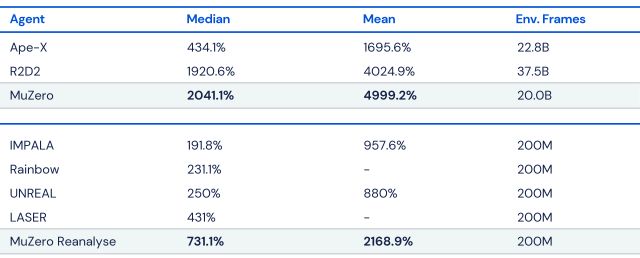
الگوریتم هوش مصنوعی DeepMind
این هوش مصنوعی نیز سه عامل مهم برای تصمیم گیری خود در نظر میگیرد. نتیجه تصمیم قبلی خود، موقعیت فعلی که در آن قرار دارد و بهترین اقدام برای انجام اقدامات بعدی! این رویکرد به ظاهر ساده، MuZero را به موثرترین الگوریتم DeepMind ساخته شده تا به امروز تبدیل کرده است. MuZero در شطرنج، Go و shogi به اندازه AlphaZero خوب است و در بازیهای آتاری از همه الگوریتمهای قبلی خود (از جمله Agent57) بهتر است. از طرف دیگر هرچه زمان بیشتری برای بررسی یک عمل به MuZero اختصاص یابد، نتیجه بهتری حاصل خواهد شد.
کسب امتیازات بالا در بازیهای آتاری هم جالب است، اما در مورد کاربردهای عملی آخرین تحقیقات DeepMind چه میتوان گفت؟ در یک کلام، میتواند پیشگامانه باشند. گفته شده که تواناییهای یادگیری MuZero میتواند روزی به ما کمک کند تا مشکلات پیچیدهای را در زمینههایی مانند رباتیک که قوانین سادهای ندارند، برطرف کنیم.


















دیدگاهتان را بنویسید