



پژوهشگران اپل نسخهای بهبودیافته از مدل SlowFast-LLaVA را توسعه دادهاند که توانسته است در تحلیل و درک ویدئو های طولانی از مدلهای بزرگتر عملکرد بهتری نشان دهد. این موضوع اهمیت زیادی دارد، زیرا پردازش ویدئوهای طولانی یکی از چالشهای اصلی مدلهای زبانی تصویری محسوب میشود.
این روزها بیشتر صحبتها درباره ابزارها و مدلهای هوش مصنوعی تولید ویدئو است که در ماههای گذشته در مورد برخی آنها مثل Sora، Veo، Flow، Pictory یا Runway AI اطلاعاتی را با شما به اشتراک گذاشتیم. اما کمتر به مدلهایی پرداخته میشود که هدفشان درک و تحلیل ویدئوهای طولانی است. در این مطلب قرار است به سراغ نوآوری اپل برویم؛ جاییکه پژوهشگران این شرکت با معرفی مدل جدیدی توانستهاند گام مهمی در فهم دقیق ویدئو ها بردارند و حتی در برخی موارد از رقبای بزرگتر هم جلو بزنند.
بخش فنی موضوع
بهطور ساده، زمانیکه یک مدل زبانی بزرگ (LLM) برای درک ویدئو آموزش داده میشود، ویدئو را به فریمها تقسیم کرده و با استفاده از بینایی کامپیوتری ویژگیهای بصری هر فریم را استخراج میکند. سپس دگرگونی این ویژگیها در گذر زمان را ارزیابی کرده و در نهایت همه دادهها را با زبان همسو میسازد تا بتواند محتوای ویدئو را به شکل متنی توصیف یا تحلیل نماید.
یک روش بسیار ناکارآمد برای این کار تحلیل تکتک فریمهای ویدئو است؛ روشی که حجم عظیمی از اطلاعات تکراری تولید میکند، زیرا اغلب فریمها تغییرات معناداری نسبت به فریم قبل ندارند.
وجود این حجم عظیم دادههای تکراری میتواند بهراحتی باعث شود مدل زبانی از پنجره زمینه (context window) خود فراتر برود. پنجره زمینه حداکثر مقدار اطلاعاتی است که مدل میتواند در یک زمان پردازش و نگهداری کند. زمانیکه این ظرفیت پر میشود، مدل برای ادامه پردازش، اطلاعات قدیمیتر را کنار میگذارد تا فضای کافی برای دادههای جدید داشته باشد.
البته روشهای کارآمدتری نیز برای آموزش مدلهای ویدئویی وجود دارد. برای نمونه، شرکت انویدیا بهتازگی مقالهای در این زمینه منتشر کرده است. اما در مجموع این توضیح، اساس درک پژوهش اپل را شکل میدهد.
مطالعه اپل
به گفته پژوهشگران اپل، مدل های زبانی بزرگ ویدئو یی (Video LLMs) ادراک ویدئویی را با مدلهای زبانی از پیش آموزشدیده ترکیب میکنند تا بتوانند ویدئوها را پردازش کرده و به دستورات کاربران پاسخ دهند. هرچند پیشرفتهای چشمگیری حاصل شده، اما همچنان محدودیتهای قابلتوجهی در این مدلها وجود دارد.
این محدودیتها به گفته آنها سه دستهاند:
- مدلهای موجود معمولاً به پنجرههای زمینه طولانی و تعداد بسیار زیادی فریم وابستهاند که ناکارآمد است و قابلیت انتقال به مدلهای کوچکتر را سخت میکند.
- بیشتر آنها به فرآیندهای آموزشی چندمرحلهای و پیچیده نیاز دارند که اغلب از دادههای خصوصی استفاده میکنند و بازتولید آنها دشوار است.
- بسیاری از آنها تنها برای وظایف ویدئویی بهینه شدهاند و درک تصاویر را به خوبی مدلهای عمومی ندارند.
اپل برای رفع این محدودیتها ابتدا به مدل SlowFast-LLaVA توجه کرد؛ یک مدل متنباز که پیشتر نتایج امیدوارکنندهای با ترکیب نشانههای مکانی و زمانی به دست آورده بود. این مدل از دو جریان استفاده میکرد:
- یک جریان کند (Slow stream) که فریمهای کمتر اما با جزئیات بالاتر را پردازش میکند تا محتوای صحنه را دریابد.
- یک جریان سریع (Fast stream) که فریمهای بیشتری با جزئیات کمتر بررسی میکند تا حرکتها و تغییرات در طول زمان دنبال شود.
اپل ابتدا این مدل را با تصاویر تنظیم دقیق (fine-tune) کرد تا توانایی استدلال بصری عمومی را تقویت کند. سپس آن را بهطور همزمان با تصاویر و ویدئوها (از مجموعهدادههای عمومی) آموزش داد تا ساختارهای زمانی را بدون کاهش توانایی درک تصاویر بیاموزد.
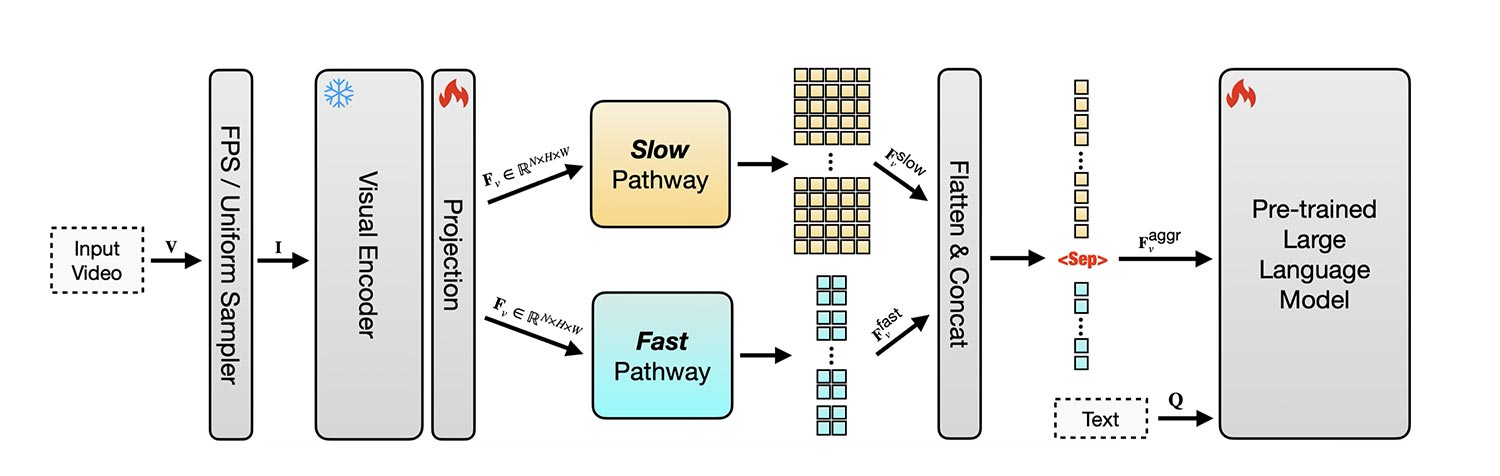
نتیجه این تلاشها به شکلگیری SlowFast-LLaVA-1.5 (SF-LLaVA-1.5) انجامید؛ مجموعهای از مدلها در سه اندازه با 1B، 3B و 7B پارامتر. این مدلها توانستند در بسیاری از وظایف ویدئویی عملکردی بهتر از مدلهای بسیار بزرگتر داشته باشند و حتی در بعضی موارد همانطور که پژوهشگران اپل گفتهاند، با اختلاف قابلتوجهی از آنها پیشی بگیرند.
در واقع، در معیارهای ویدئو های طولانی مانند LongVideoBench و MLVU، مدل اپل توانسته است در همه اندازهها، حتی در کوچکترین نسخه 1B، رکوردهای جدیدی ثبت کند.
علاوه بر این، مدل توانست یکی از سه محدودیت یادشده را پشت سر بگذارد و در وظایف تصویری نیز نتایج خوبی نشان دهد؛ از جمله در آزمونهای دانش عمومی، استدلال ریاضی، OCR و سناریوهای متنی-تصویری. تیم پژوهش حتی چندین استراتژی فشردهسازی ویدئو را آزمایش کرد، اما دریافت که تنظیمات انتخابشده بهترین تعادل میان سرعت، دقت و تعداد توکنها را ارائه میدهد.
محدودیتهای باقیمانده
با وجود این پیشرفتها، پژوهشگران اپل برای مدل SF-LLaVA-1.5 حداکثر طول ورودی 128 فریم را در نظر گرفتند.
این یعنی چه ویدئو تنها چند دقیقه باشد و چه چند ساعت، مدل همیشه حداکثر 128 فریم را پردازش میکند: 96 فریم به صورت یکنواخت برای جریان سریع انتخاب میشوند و 32 فریم نیز برای جریان کند.
پژوهشگران با توجه به این موضوع میگویند: این رویکرد ممکن است برخی فریمهای کلیدی را در ویدئوهای طولانی از دست بدهد و مدل را در مورد سرعت پخش ویدئو گمراه کند. (…) عملکرد SF-LLaVA-1.5 میتواند با تنظیم تمام پارامترها از جمله رمزگذار بصری بهبود یابد. با این حال، این کار برای مدلهای ویدئوی طولانی ساده نیست، زیرا حافظه GPU بالایی برای ذخیره مقادیر فعالسازی نیاز دارد. مطالعات آینده میتوانند به ادغام تکنیکهای صرفهجویی در حافظه مانند Stochastic BP بپردازند.
با این حال، رویکرد اپل باعث شد این مدل به یک مدل پیشرفته در سطح جهانی تبدیل شود، آن هم با این مزیت که فقط بر اساس مجموعهدادههای عمومی آموزش دیده است. SF-LLaVA-1.5 اکنون به صورت متنباز در GitHub و Hugging Face دردسترس است و متن کامل این پژوهش نیز در arXiv منتشر شده است.























دیدگاهتان را بنویسید