



انویدیا قصد دارد با گرافیکهای نسل بعدی Feynman، جایگاه خود را در بخش inference «استفاده عملی از مدلهای هوش مصنوعی آموزشدیده» تثبیت کند، زیرا این شرکت احتمالاً واحدهای LPU را بهعنوان بخشی از معماری آینده ادغام خواهد کرد.
برنامه انویدیا برای تسلط بر inference با معماری Feynman
انویدیا میتواند با بهرهگیری از رویکردی مشابه X3D شرکت AMD، واحدهای LPU شرکت Groq را تا سال 2028 به گرافیکهای Feynman اضافه کند؛ این واحدها بهصورت دایهای مجزا و انباشتهشده طراحی خواهند شد. هدف اصلی از این تصمیم، پیشتازی در بخش inference و بهینهسازی اجرای مدلهای هوش مصنوعی در مقیاس بالا عنوان میشود.
استفاده احتمالی از hybrid bonding و دایهای SRAM
توافق لایسنس مالکیت فکری Team Green برای واحدهای LPU شرکت Groq در نگاه اول توسعهای محدود به نظر میرسد، اما در عمل نشاندهنده برنامه انویدیا برای تصاحب رهبری در زمینه inference از طریق LPUها بهشمار میآید؛ موضوعی که پیشتر نیز بهصورت مفصل بررسی شده بود. درباره نحوه ادغام LPUها، سناریوهای مختلفی مطرح شدهاند؛ با این حال، بر اساس تحلیل AGF، کارشناس شناختهشده گرافیک، انویدیا احتمالاً از فناوری hybrid bonding شرکت TSMC برای انباشتن واحدهای LPU روی گرافیکهای Feynman استفاده خواهد کرد.
شباهت به رویکرد X3D و محدودیتهای SRAM
AGF معتقد است پیادهسازی این ساختار میتواند شباهت زیادی به آنچه AMD در پردازندههای X3D انجام داده داشته باشد؛ جایی که فناوری SoIC hybrid bonding شرکت TSMC برای اتصال کاشیهای 3D V-Cache به دای محاسباتی اصلی بهکار گرفته شد. از دید این کارشناس، ادغام SRAM بهصورت یک دای یکپارچه برای گرافیکهای Feynman انتخاب مناسبی بهنظر نمیرسد، زیرا مقیاسپذیری SRAM محدود بوده و تولید آن روی نودهای پیشرفته منجر به هدررفت سیلیکون ردهبالا و افزایش چشمگیر هزینه استفاده از هر سطح ویفر خواهد شد. بر همین اساس، انباشتن واحدهای LPU روی دای محاسباتی Feynman راهکار منطقیتری ارزیابی میشود.
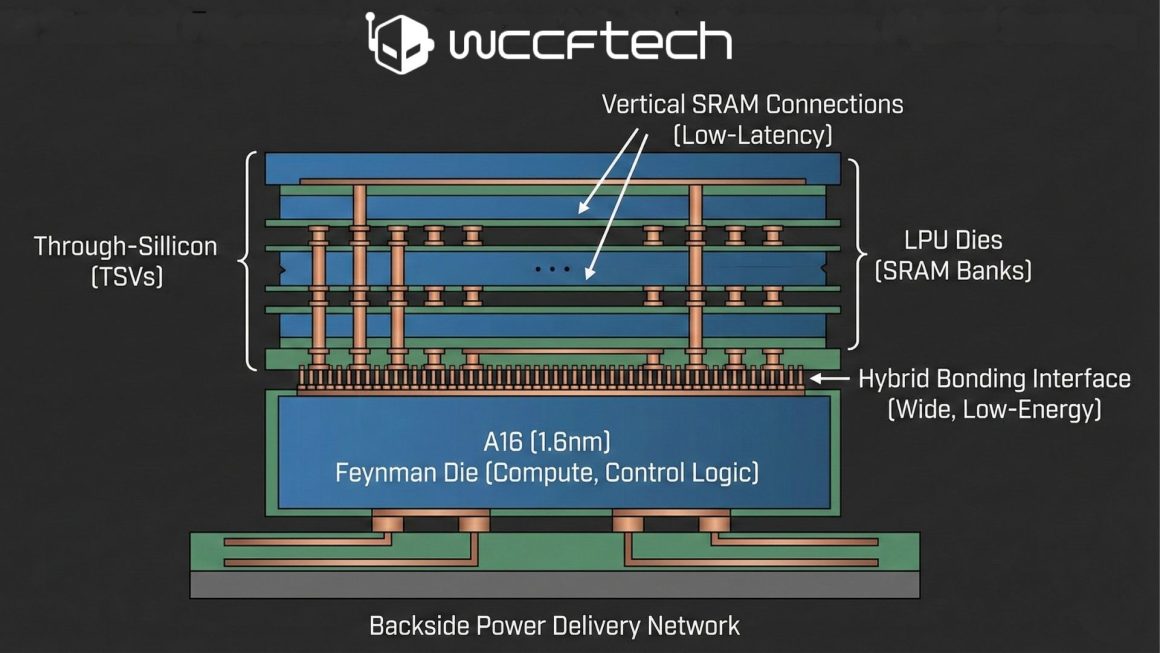
مزایا و چالشهای فنی طراحی چنددای
در این رویکرد، استفاده از نود A16 با لیتوگرافی 1.6 نانومتر برای دای اصلی Feynman که شامل بلوکهای محاسباتی مانند واحدهای tensor و منطق کنترلی میشود در نظر گرفته خواهد شد؛ در حالی که دایهای مجزای LPU میزبان بانکهای بزرگ SRAM خواهند بود. برای اتصال این دایها، فناوری hybrid bonding شرکت TSMC نقشی کلیدی ایفا میکند، زیرا امکان ایجاد رابطی عریضتر و مصرف انرژی کمتر بهازای هر بیت را نسبت به حافظههای خارج از پکیج فراهم میسازد. افزون بر این، وجود سیستم تأمین توان از پشت در A16 فضای جلویی دای را برای اتصال عمودی SRAM آزاد میکند و در نتیجه پاسخ decode با تأخیر پایینتری ارائه خواهد شد.

محدودیتهای حرارتی و پیامدهای اجرایی
با وجود منطقیبودن این طراحی، مدیریت محدودیتهای حرارتی چالشی جدی محسوب میشود، زیرا انباشتن دایها روی فرایندی با چگالی محاسباتی بالا از پیش نیز دشوار بوده و تمرکز LPUها بر توان عملیاتی پایدار میتواند گلوگاههایی ایجاد کند. در سطح اجرایی، پیامدها پیچیدهتر خواهند شد، چرا که LPUها بر ترتیب اجرای ثابت تکیه دارند و این موضوع تضادی ذاتی میان قطعیت و انعطافپذیری ایجاد میکند.
حتی در صورت حل محدودیتهای سختافزاری، نگرانی اصلی به رفتار CUDA در محیطهای مبتنی بر LPU بازمیگردد؛ جایی که نیاز به تعیین صریح محل حافظه وجود دارد، در حالی که کرنلهای CUDA بر پایه انتزاع سختافزاری طراحی شدهاند. ادغام SRAM در معماریهای هوش مصنوعی برای Team Green کار سادهای نخواهد بود و به مهندسی بسیار پیچیدهای نیاز دارد تا محیطهای ترکیبی LPU و گرافیک بهخوبی بهینه شوند؛ با این حال، بهنظر میرسد انویدیا در صورت تمایل به رهبری بازار inference، آماده پرداخت این هزینه باشد.





















دیدگاهتان را بنویسید