



شتاب دهندههای هوش مصنوعی Gaudi 2 شرکت اینتل مناسبترین جایگزین برای تراشههای کمپانی انویدیا هستند و Hugging Face توانایی تولید متن خود را با استفاده از Llama 2 نشان داده است.
شتابدهندههای Gaudi 2 شرکت اینتل در نسل متن با استفاده از Llama 2 LLM منبع باز با حداکثر 70 میلیارد پارامتر آزمایش شدند
همانطور که شرکت اینتل اکوسیستم نرم افزاری هوش مصنوعی خود را گسترش میدهد، این شرکت محبوبترین بارهای کاری هوش مصنوعی را هدف قرار خواهد داد که شامل LLM (مدلهای زبان بزرگ) میشود. این کار با استفاده از قابلیت Habana Optimum که به عنوان کتابخانههای ترانسفورماتور و دیفیوزر رابط عمل میکند و همچنین پردازندههای اینتل Habana Gaudi مانند Gaudi 2، امکانپذیر شده است. این شرکت قبلاً قابلیتها و عملکرد پردازندههای Gaudi 2 خود را در مقابل چیپهای گرافیکی A100 کمپانی انویدیا نشان داده است که یکی از گزینههای محبوب در بازار محسوب میشود، اما Gaudi 2 در ارائه عملکرد سریعتر در TCO عملکرد قابل ستایشی را به نمایش میگذارد.
به عنوان آخرین نمایش، Hugging Face سهولت تولید متن با Llama 2 (7b, 13b, 70b) را با استفاده از دستورالعمل Optimum Habana و شتابدهنده هوش مصنوعی Gaudi 2 شرکت اینتل نشان میدهد. نتیجه نهایی بیانگر آن است که تراشه Gaudi 2 نه تنها میتوانست درخواستهای تک/چندگانه را بپذیرد، بلکه استفاده از آن بسیار آسان بود و همچنین میتوانست پلاگینهای سفارشی را در اسکریپتها کنترل کند.
با رشد کامل انقلاب هوش مصنوعی مولد (GenAI)، تولید متن با مدلهای ترانسفورماتور منبع باز مانند Llama 2 به بحث روز تبدیل شده است. علاقهمندان به هوش مصنوعی و همچنین توسعه دهندگان به دنبال بهره بردن از تواناییهای تولیدی چنین مدلهایی برای موارد استفاده و برنامههای کاربردی خود هستند. این مقاله نشان میدهد که تولید متن با مدلهای خانواده Llama 2 (7b، 13b و 70b) با استفاده از Optimum Habana و یک دستورالعمل کلاس سفارشی چقدر آسان است، شما میتوانید مدلها را تنها با چند خط کد اجرا کنید!
این دستورالعمل کلاس سفارشی برای ارائه انعطاف پذیری و سهولت استفاده طراحی شده است. علاوه بر این، سطح بالایی از انتزاع را فراهم میکند و فرایند تولید متن را از ابتدا تا انتها انجام میدهد که شامل پیشپردازش و پسپردازش متن است. راههای مختلفی برای استفاده از دستورالعمل وجود دارد، میتوانید
run_pipeline.pyاسکریپت را از مخزن Optimum Habana اجرا کنید، کلاس pipeline را به اسکریپتهای پایتون خود اضافه کنید یا کلاسهای LangChain را با آن مقداردهی اولیه کنید.ما یک دستورالعمل تولید متن سفارشی در شتابدهنده هوش مصنوعی Intel Gaudi 2 ارائه کردیم که یک یا چند اعلان را به عنوان ورودی میپذیرد. این دستورالعمل از نظر اندازه مدل و همچنین پارامترهای موثر بر کیفیت تولید متن انعطاف پذیری زیادی را ارائه میدهد. علاوه بر این، استفاده از آن و اتصال به اسکریپتهای شما بسیار آسان است و با LangChain سازگار خواهد بود.
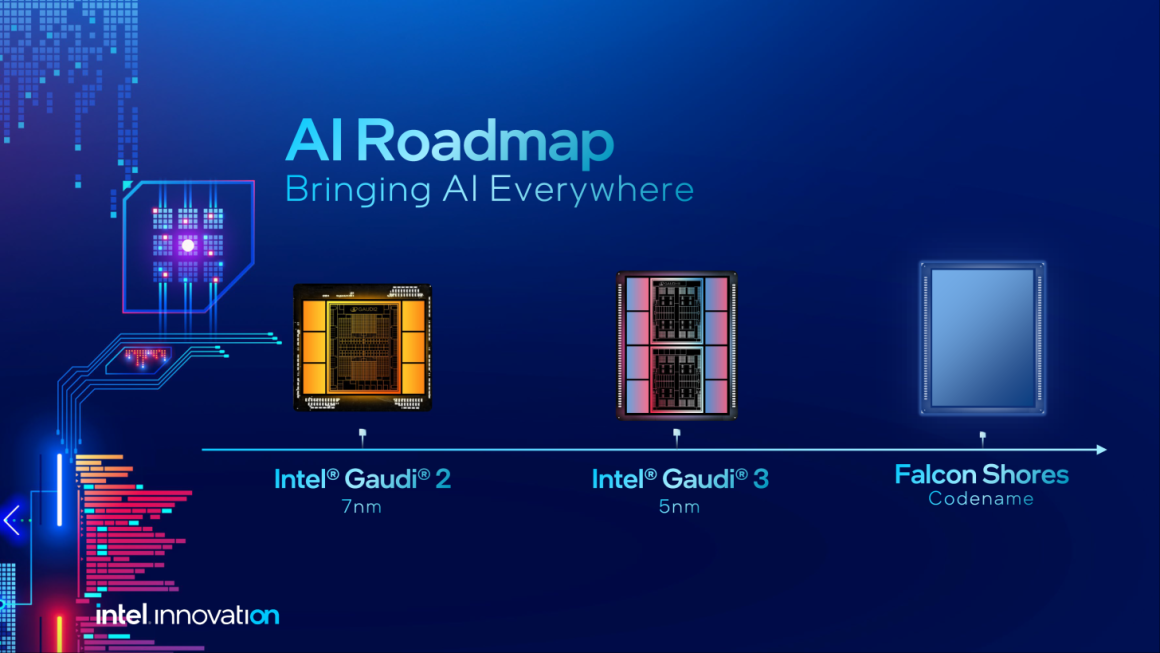
شرکت اینتل متعهد است که بخش هوش مصنوعی خود را در سالهای آینده شتاب دهد. امسال، این شرکت برنامههایی برای معرفی سومین نسخه از Gaudi به نام Gaudi 3 دارد که انتظار میرود از یک گره فرآیند 5 نانومتری استفاده کند و طبق گزارشها سریعتر از H100 شرکت انویدیا خواهد بود اما قیمت آن بسیار پایینتر است. به طور مشابه، این شرکت همچنین قصد دارد به سمت یک طراحی کاملا داخلی با نسل بعدی چیپ گرافیکی Falcon Shores که عرضه آن برای سال 2025 پیشبینی میشود، حرکت کند. این شرکت همچنین در حال باز کردن قابلیتهای هوش مصنوعی مانند رابط Llama 2 با PyTorch برای سطح مصرفکننده خود یعنی چیپهای گرافیکی Arc سری A است.
- پردازنده دسکتاپ Arrow Lake-S اینتل با 24 هسته و 24 رشته، بدون پشتیبانی از AVX512 مشاهده شد
- پردازندههای دسکتاپ Bartlett Lake-S اینتل ممکن است دارای 12 هسته P باشند
- تراشه های اینتل در آلمان به دلیل اختلافات مربوط به حق اختراع ممنوع شدند
- تکنولوژی فیلتر شارپ کننده تطبیقی در Lunar Lake اینتل با معماری iGPU Xe2 Battlemage به بازار میآید





















دیدگاهتان را بنویسید