



پتنت انویدیا با هدف غلبه بر یکی از بزرگترین چالشهای محاسبات هوش مصنوعی، راهکاری نوآورانه برای افزایش سرعت و کارایی گرافیک ارائه میدهد. این فناوری با بومیسازی پردازشها، تأخیر را کاهش داده و قدرت برنامههای هوش مصنوعی را بهطور چشمگیری ارتقا میبخشد. انویدیا همچنان با اقتدار در خط مقدم محاسبات مبتنی بر گرافیک پیشتازی میکند و به همین دلیل، سلطهای بینظیر بر عرصهی هوش مصنوعی دارد. به نظر میرسد انویدیا دستکم در حال حاضر، نوآوریهای فراوانی را به ارمغان میآورد.
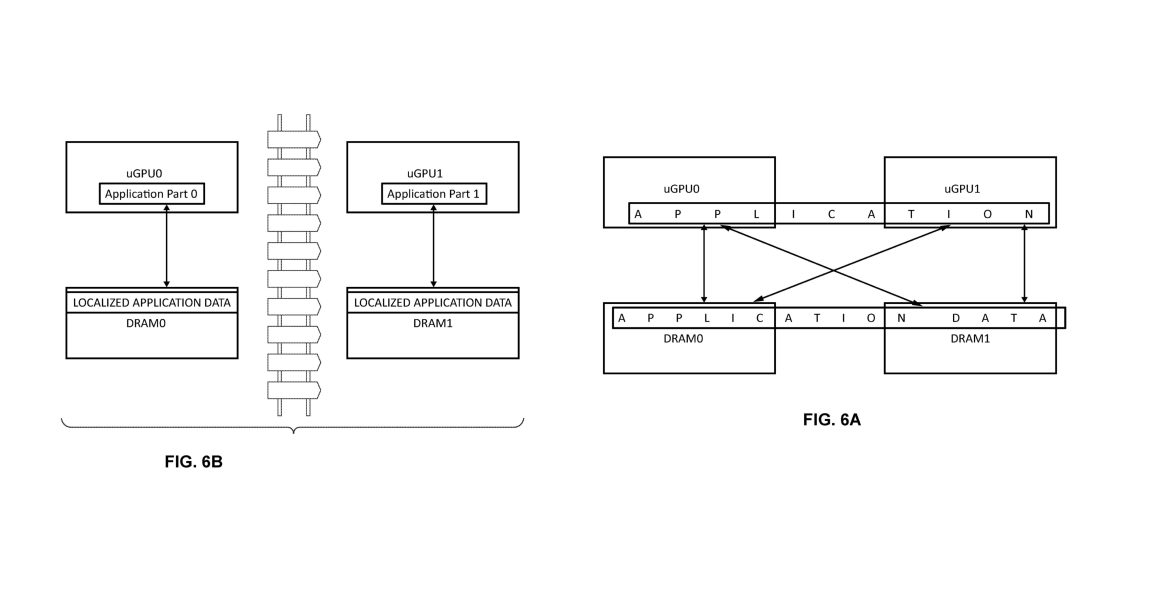
به نقل از WCCFTech، انویدیا در تاریخ ۶ مارس ۲۰۲۵ (16 اسفند 1403) برای یک پتنت جدید با شماره انتشار US20250078199A1 درخواست داد. این پتنت، بخشهای مجزای یک گرافیک را در نظر میگیرد که در محدودههای محلی برای ذخیره و دسترسی به دادهها و انجام محاسبات کار میکنند، و به این ترتیب، تأخیرهای دسترسی به منابع محاسباتی با فاصله دور را کاهش میدهند. نیازی به گفتن نیست که تحقق فیزیکی این پتنت، سرعت محاسبات مبتنی بر گرافیک را به طور قابل توجهی افزایش میدهد، که باید امکان کاربردهای هوش مصنوعی به مراتب قدرتمندتری را فراهم کند.
اجزای اصلی پتنت انویدیا
پتنت انویدیا برای دستیابی به این بومیسازی، سه جزء کلیدی را در نظر گرفته است:
- واحد AMAP: این واحد یک دیدگاه جایگزین از حافظه محلی ارائه میدهد و امکان بازنگاری مجدد حافظه فیزیکی به DRAM مرتبط محلی تعیینشده با یک uGPU (گرافیک میکرو) را فراهم میکند.
- سیستم GPC: این سیستم تخصیص یک برنامه محاسباتی به GPCهای خاص را امکانپذیر میکند و اجرای آن را به یک گره uGPU محدود میکند.
- مدیر منابع گرافیک: این بخش نقش هماهنگی و مدیریت منابع را بر عهده دارد.
محلی سازی گرافیک چگونه کار میکند؟
برنامه هوش مصنوعی میتواند از طریق ماسک Affinity به درایور CUDA اطلاع دهد که قصد دارد به یک گره uGPU خاص متصل شود. سپس درایور CUDA با مدیر منابع هماهنگ میشود تا بازنگاری محلی را اعمال کند. همزمان، حافظهای که با یک گره uGPU خاص همتراز است، به آن گره اختصاص داده میشود. پس از آن، درایور CUDA کار محاسباتی را به GPCهایی که توسط گره uGPU تعیینشده کنترل میشوند، تخصیص میدهد. همچنین، نود های CTA با استفاده از بازنگاری آدرس محلی به حافظه دسترسی دارند، در حالی که درخواستهای حافظه به DRAM محلی یک uGPU محدود میشوند.
مزایای این معماری
معماری مورد نظر انویدیا، فواید زیر را به همراه دارد:
- کاهش قابل توجه تأخیرهای مربوط به دسترسی به حافظه
- افزایش کارایی کش با حذف ذخیرهسازی دادههای اضافی
- حل مشکلات تأخیر در ارتباطات بین die
- ارائه کنترل دقیقتر به کاربردها بر تخصیص و استفاده از منابع گرافیک
این پتنت میتواند به عنوان راهی دیگر برای غلبه بر محدودیتهای مرتبط با قانون مور عمل کند. قانون مور بر کوچکسازی برای افزایش عملکرد تکیه دارد، اما این پتنت به جای آن، بر بومیسازی تمرکز میکند تا محاسبات را سرعت ببخشد.
در برخی جنبهها، این رویکرد مشابه روشی است که توسط DeepSeek به کار گرفته شده است. این استارتاپ هوش مصنوعی چینی توانست قابلیتهای اضافی گرافیک های نسل قدیمی انویدیا را فعال کند و بهبود قابل توجهی در منابع محاسباتی موجود ایجاد نماید.






















دیدگاهتان را بنویسید