



انویدیا جزئیات کامل سریعترین تراشه هوش مصنوعی خود را با نام Blackwell Ultra GB300 منتشر کرد؛ تراشهای که 50 درصد سریعتر از GB200 عمل میکند و به حافظه 288 گیگابایت مجهز شده است.
همزمان با کاهش قیمت کارتهای گرافیک سری RTX 50 در بریتانیا و اروپا، انویدیا در گیمزکام 2025 از مجموعهای از نوآوریهای گرافیکی، از جمله ارتقاء سرویس GeForce Now و قابلیتهای تازه در Nvidia App گرفته تا معرفی فناوری واقعگرایانه موی RTX پرده برداشت. همچنین، باندل اختصاصی بازی Borderlands 4 برای دارندگان RTX 50 نشان میدهد که انویدیا علاوهبر هوش مصنوعی، تمرکز ویژهای بر تجربه گیمینگ نسل جدید دارد.
تراشه Blackwell Ultra GB300؛ معجزه انویدیا برای هوش مصنوعی
چند روز پیش انویدیا مقالهای منتشر کرد که در آن به بررسی دقیق جدیدترین و قدرتمندترین تراشه هوش مصنوعی خود یعنی Blackwell Ultra GB300 پرداخت. این تراشه وارد مرحله تولید انبوه شده و هماکنون در اختیار مشتریان کلیدی قرار دارد. هرچند این تراشه نسخه توسعهیافته معماری Blackwell محسوب میشود، اما از نظر کارایی و قابلیتها ارتقای چشمگیری به همراه دارد.

همانطور که سری Super انویدیا نسخه پیشرفته کارتهای گرافیک RTX برای بازی به شمار میرود، سری Ultra نیز نسخه بهینهشده تراشههای هوش مصنوعی معرفیشده پیشین است. در معماریهای Hopper و Volta نسخه Ultra وجود نداشت، اما مدلهای بهبودیافته آنها به نوعی چنین نقشی را ایفا میکردند. علاوه بر برتری سختافزاری، بهینهسازیهای نرمافزاری نیز به افزایش کارایی مدلهای غیر Ultra کمک میکنند.
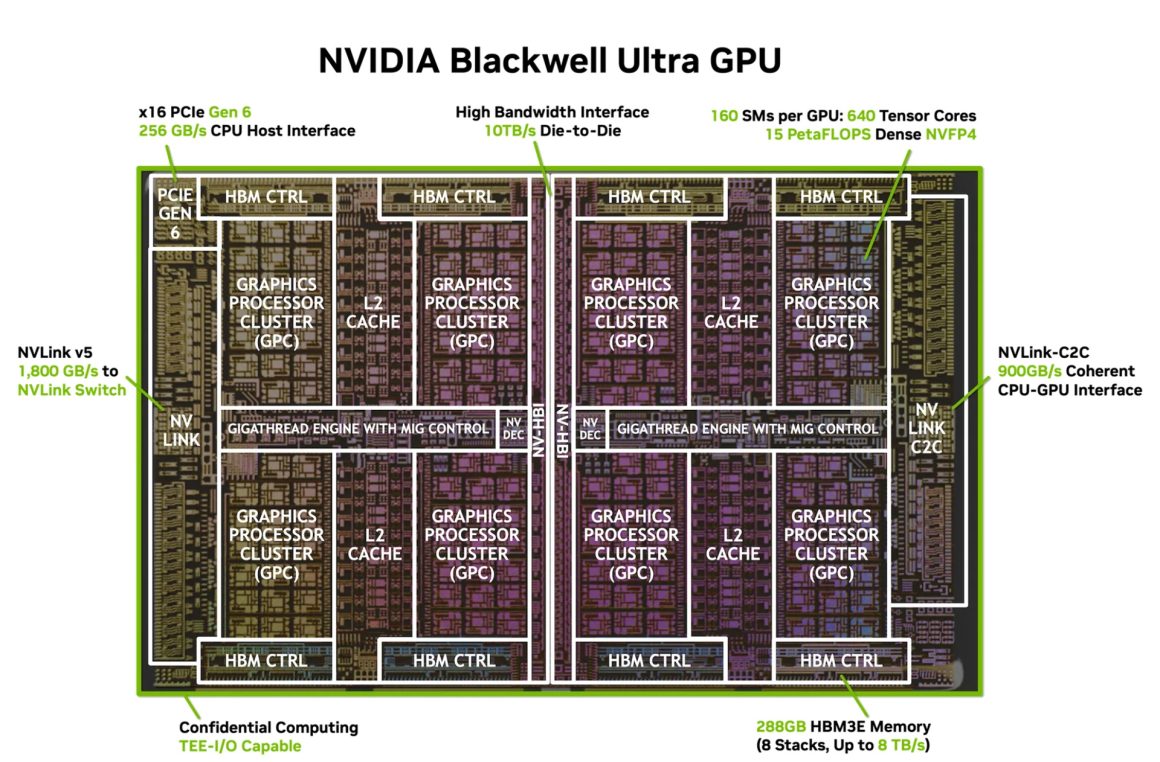
مشخصات کلی Nvidia Blackwell Ultra GB300
نسخه GB300 به عنوان یک گرافیک پیشرفته از دو قالب Reticle تشکیل شده که به وسیله رابط پهنای باند بالای NV-HBI به یکدیگر متصل شده و در نهایت به صورت یک تراشه واحد عمل میکنند. این گرافیک با فناوری TSMC 4NP «نسخه بهینه 5 نانومتری برای انویدیا» تولید شده و 208 میلیارد ترانزیستور در خود جای داده است. رابط NV-HBI پهنای باند 10 ترابایت بر ثانیه را میان دو قالب گرافیک فراهم میکند و عملکردی یکپارچه ارائه میدهد.

این کارت گرافیک شامل 160 واحد SM است که هرکدام 128 هسته CUDA، چهار هسته Tensor نسل پنجم با پشتیبانی از FP8، FP6 و NVFP4، حافظه Tensor یا TMEM با ظرفیت 256 کیلوبایت و واحدهای SFU دارند. در مجموع این مشخصات به 20480 هسته CUDA و 640 هسته Tensor به همراه 40 مگابایت حافظه TMEM میرسند.
مقایسه Hopper، Blackwell و Blackwell Ultra
| ویژگی | Hopper | Blackwell | Blackwell Ultra |
| فناوری ساخت | TSMC 4N | TSMC 4NP | TSMC 4NP |
| تعداد ترانزیستور | 80B | 208B | 208B |
| تعداد قالب GPU | 1 | 2 | 2 |
| عملکرد NVFP4 | – | 10 | 20 PetaFLOPS |
| عملکرد FP8 | 2 | 4 PetaFLOPS | 5 |
| تسریع Attention | 4.5 TeraExponentials/s | 5 TeraExponentials/s | 10.7 TeraExponentials/s |
| حداکثر ظرفیت حافظه HBM | 80 گیگابایت HBM «H100»؛ 141 گیگابایت HBM3E «H200» | 192 گیگابایت HBM3E | 288 گیگابایت HBM3E |
| حداکثر پهنای باند HBM | 3.35 ترابایت بر ثانیه «H100»؛ 4.8 TB/s «H200» | 8 ترابایت بر ثانیه | 8 ترابایت بر ثانیه |
| پهنای باند NVLink | 900 گیگابایت بر ثانیه | 1800 گیگابایت بر ثانیه | 1800 گیگابایت بر ثانیه |
| حداکثر توان مصرفی «TGP» | تا 700 وات | تا 1200 وات | تا 1400 وات |
هستههای Tensor نسل پنجم؛ قلب پردازش هوش مصنوعی
تمام عملیات محاسباتی هوش مصنوعی توسط هستههای Tensor نسل پنجم انجام میشود. انویدیا در هر نسل نوآوری بزرگی در این بخش ارائه کرده است:
- Volta؛ واحدهای MMA با 8 نخ پردازشی و FP16 همراه با FP32 برای آموزش
- Ampere؛ اجرای MMA در سطح Warp کامل با فرمتهای BF16 و TensorFloat-32
- Hopper؛ واحد MMA در گروه Warp با 128 نخ و موتور Transformer با پشتیبانی از FP8
- Blackwell؛ موتور Transformer نسل دوم با FP8، FP6 و NVFP4 به همراه حافظه TMEM
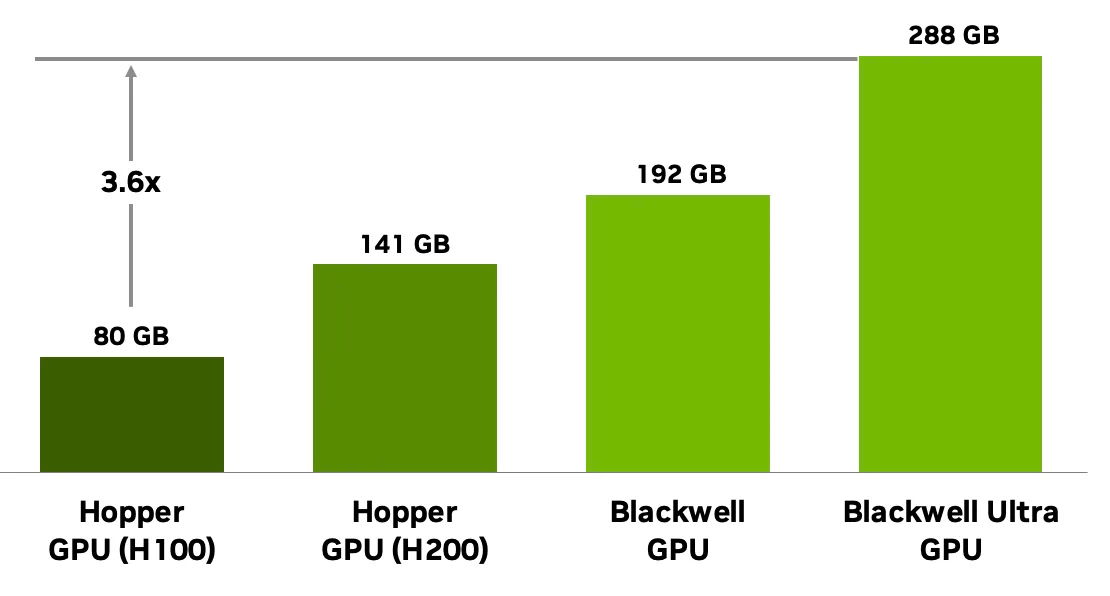
ارتقای حافظه در Blackwell Ultra
این نسخه با حافظه 288 گیگابایت HBM3e در 8 پشته و رابط 8192 بیتی با پهنای باند 8 ترابایت بر ثانیه عرضه میشود. در حالیکه مدل GB200 تنها 192 گیگابایت داشت، این ارتقا امکان پشتیبانی از مدلهای هوش مصنوعی با تریلیونها پارامتر را فراهم میکند. مزایا شامل:
- اجرای مدلهای 300B+ پارامتر بدون نیاز به جابجایی حافظه
- افزایش طول زمینه در مدلهای Transformer به کمک ظرفیت بیشتر KV Cache
- بهبود نسبت محاسبه به حافظه در بارهای کاری متنوع
اتصالات و ارتباطات داده
ارتباط در این گرافیک توسط NVLink نسل پنجم، NVLink-C2C و رابط PCIe Gen6 x16 برقرار میشود. ویژگیها شامل:
- پهنای باند دوطرفه 1.8 ترابایت بر ثانیه به ازای هر گرافیک «18 لینک × 100 گیگابایت بر ثانیه»
- بهبود دو برابری نسبت به NVLink 4 در Hopper
- پشتیبانی از پیکربندی حداکثر 576 گرافیک در ساختار بدون انسداد
- یکپارچگی در سطح رک با چینش NVL72 شامل 72 گرافیک و پهنای باند 130 ترابایت بر ثانیه
- ارتباط CPU-GPU با NVLink-C2C و قابلیت همسانسازی حافظه با پهنای باند 900 گیگابایت بر ثانیه
جدول مقایسه اتصالات در معماریهای Hopper، Blackwell و Blackwell Ultra
| ویژگی | Hopper | Blackwell | Blackwell Ultra |
| NVLink «GPU-GPU» | 900 GB/s | 1800 GB/s | 1800 GB/s |
| NVLink-C2C «CPU-GPU» | 900 GB/s | 900 GB/s | 900 GB/s |
| رابط PCIe | 128 GB/s «Gen 5» | 256 GB/s «Gen 6» | 256 GB/s «Gen 6» |
دقت محاسباتی و بهرهوری
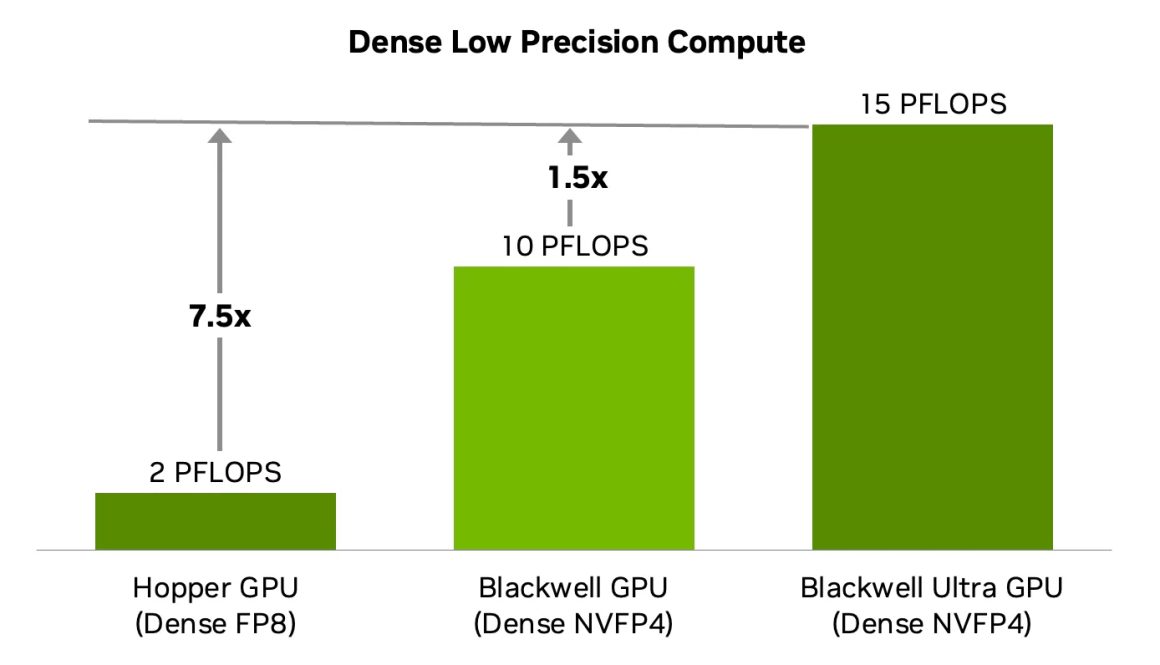
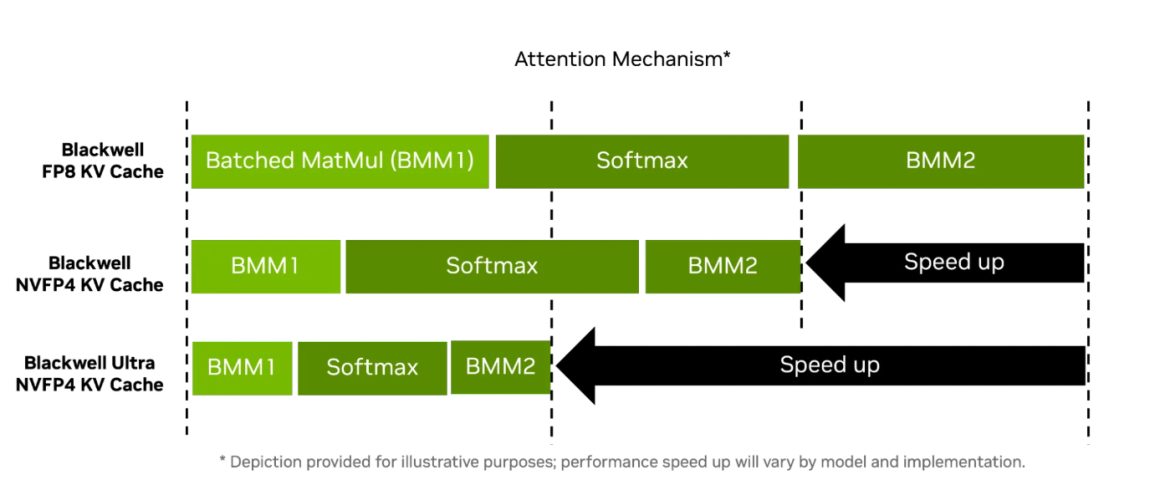
این گرافیک با استاندارد NVFP4 توان افزایش 50 درصدی در محاسبات کمدقت متراکم به دست آورده و در عین حال به دقت نزدیک به FP8 میرسد. تفاوت با FP8 معمولاً کمتر از 1 درصد است. علاوه بر این، میزان حافظه مصرفی در مقایسه با FP8 حدود 1.8 برابر کمتر و در مقایسه با FP16 حدود 3.5 برابر کمتر است.
مدیریت پیشرفته و امنیت سازمانی
Blackwell Ultra GB300 امکانات امنیتی و مدیریتی جدیدی ارائه میدهد:
- موتور GigaThread نسل جدید با زمانبندی بهینه و توزیع بهتر بار پردازشی میان 160 SM
- پشتیبانی از Multi-Instance GPU «MIG» برای تقسیم گرافیک به چند نمونه مستقل؛ بهطور مثال ایجاد دو نمونه با 140 گیگابایت حافظه یا چهار نمونه با 70 گیگابایت یا هفت نمونه با 34 گیگابایت
- رایانش محرمانه و امنیت هوش مصنوعی با TEE سختافزاری و NVLink رمزگذاریشده بدون افت پهنای باند محسوس
- موتور RAS پیشرفته با بهرهگیری از هوش مصنوعی برای پایش هزاران پارامتر، پیشبینی خرابی و بهینهسازی نگهداری



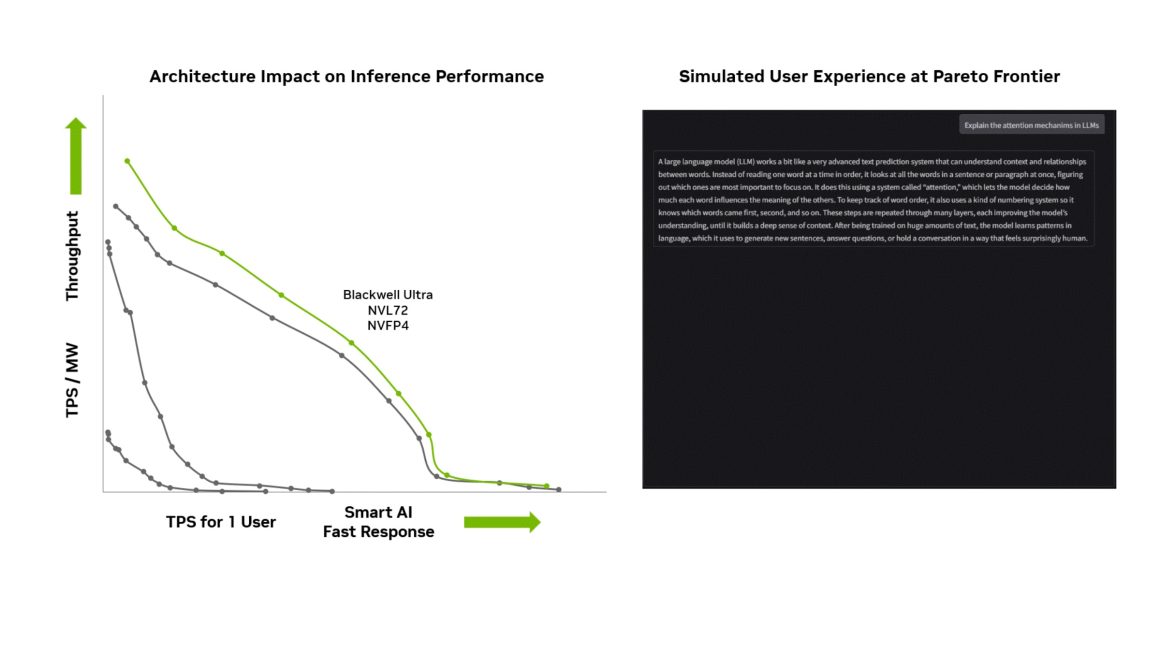
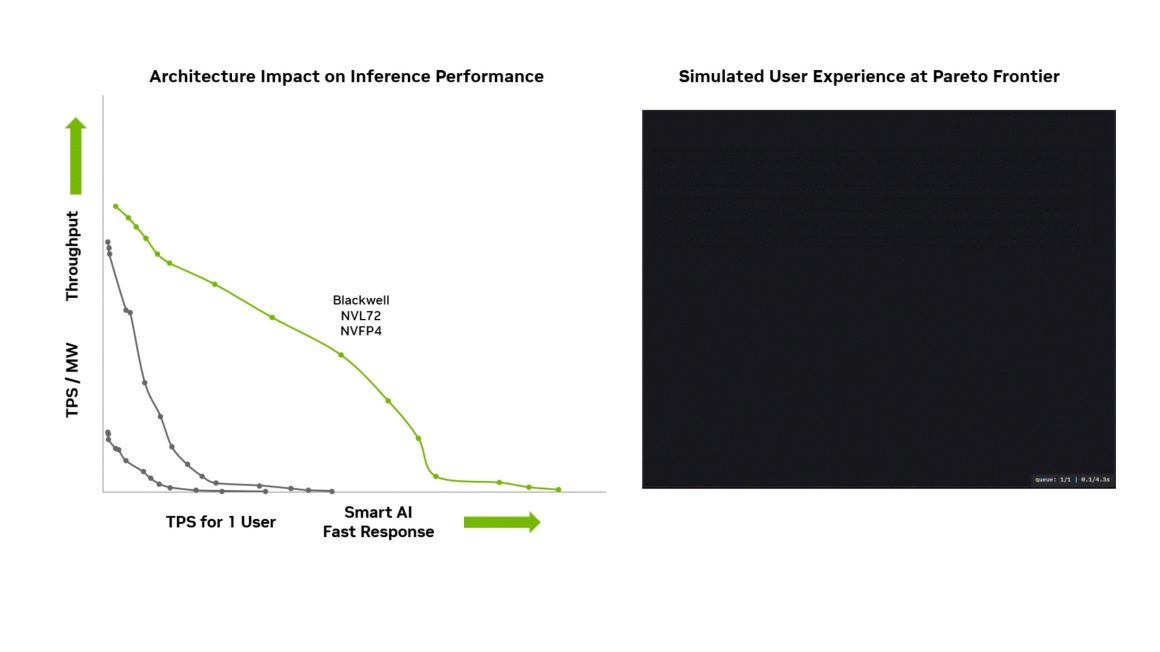
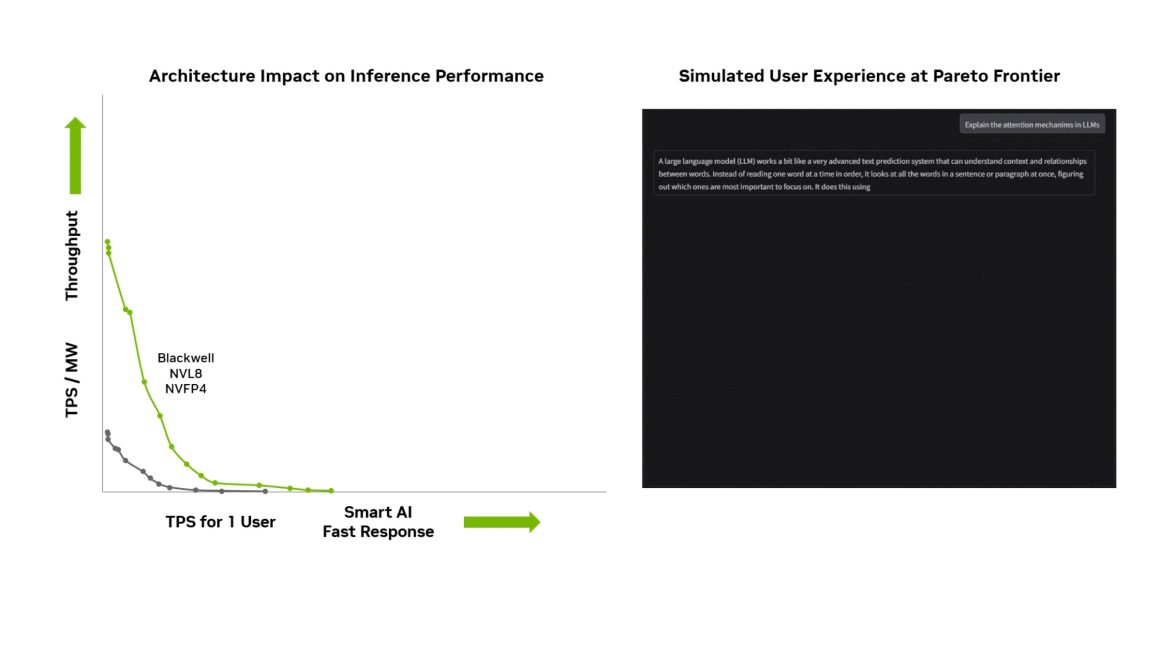
جایگاه انویدیا در آینده هوش مصنوعی
تمام این ویژگیها نشان میدهد انویدیا با تراشههای Blackwell و Blackwell Ultra در صدر فناوری هوش مصنوعی قرار دارد. پشتیبانی نرمافزاری عمیق، بهینهسازیهای مداوم و سرمایهگذاری سالانه در تحقیق و توسعه، این شرکت را برای سالهای آینده در مسیر پیشتازی حفظ خواهد کرد.





















دیدگاهتان را بنویسید